
Multithreading – a technique by which a single set of code can be used by several processors at different stages of execution. [1]
Background Information
OpenMP is an API specification for Parallel Processing specifically using shared memory. In other words, it is an API that allows you to easily implement multiple threads by simply adding a library and using the proper compiler. For the examples throughout this post I use a Late 2013 MBP retina 15″ with:
- Processor: 2.3 GHz Intel Core i7
- Memory: 16 GB 1600 MHz DDR3
- Compiler: g++-4.2
- OpenMP library
I am using OpenMP for the ease of use and because it can be integrated with ease to any current project. If you would like to maximize the speed of your program I recommend GPU programming as well as threading using the C++11 <thread> or POSIX pthread libraries.
To fully understand this post I recommend visiting my previous posts:
Cache and Threads
One of the greatest ways to improve the speed of a program is through cache optimization, once you have that down it’s time for the big leagues. Multithreading is considered one of the more difficult topics in computer science, it requires a programmer not only to understand how to manage memory, but also how to manage processes.
The Cache
A cache is a fickle friend, you can only keep so much in it at a given time yet the data is accessible 50x faster than the data in RAM. Every time a program accesses the data outside the L1 cache it sends a request outward. First to the L2 cache, then if the data is not there another request is sent to the L3 cache, and if it is not there then to RAM and the hard drive. Once the data has been located is is loaded into the next cache respectively. For example, if a data request was sent out and requests made it out the L3 cache, the data must first be loaded into the L2 cache then the L1 cache.
Why does this matter for multithreading?
Each time there is a request for new data in a particular thread the processor must wait to execute the code until it has it’s new data in it’s L1 cache. This takes time and in my previous post cache optimizing I have this lovely graph:
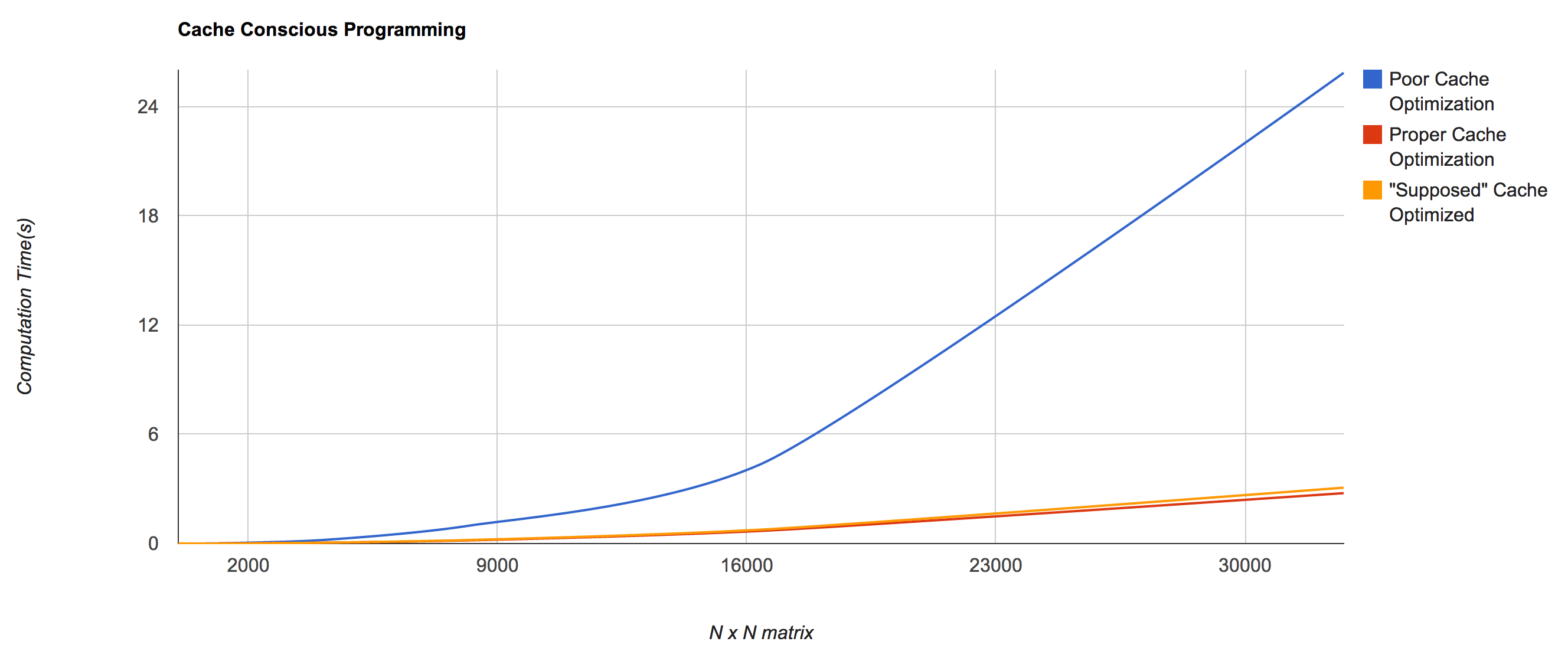
which displays how important proper cache usage really is. With multithreading cache optimizing is an even bigger deal. Imagine a program in which every piece of data requires a call out to the L3 cache, similar to the “poor cache optimization” implementation above. Now if we imagine that multiple threads can run the given program, we could constantly need to not only change out part of the L1 cache, but also change out part of the L2 cache. Why? Suppose the program was iterating over a 2D matrix (as the example problems do), if one thread starts from one corner of the matrix (lets say bottom right) and the other starts iterating from another (lets say the top left), and the matrix is 32768 x 32768 and requires 4 Gb of space with the following cache sizes:
- L1 Cache – 32Kb
- L2 Cache – 256Kb
- L3 Cache – 8Mb
- RAM – 12 Gb
This means if your program is running on two threads over different parts of the matrix, every single iteration requires a request to RAM. Each thread will also affect the others, since the L3 Cache is shared it potentially will never contain the memory from a previous request and since we know the advantages of already having prefetched memory in our cache this is a big big big big deal.
Mismanaging your cache while multithreading could have far reaching consequences including having your program never finish, or take longer than you have time for.
OpenMP Breakdown
The following are basic examples of how to properly use threads to improve a programs execution time:
This example is by far the slowest running, similar to an example from the cache optimizing post, every time the matrix is accessed the L1 cache must load a different array. This means that potentially even the L3 cache is being switched out on nearly every single iteration of ‘y,’ and I will note that as the matrix sizes become larger this blows up very quickly. Further, I am not exceptionally familiar with OpenMP and with pthreads this example would likely be much worse (since OpenMP does some optimizations for you). This programming approach takes a large amount of time, and is far worse than the similar parallelized examples. As an exercise I recommend testing the github code with a matrix size of 65536 as a max.
**The non-parallelized example took ~25 seconds to complete, the parallelized example takes ~11 seconds to complete[2].
The example above could suffer from a large speed reduction due to the lack of the “schedule(dynamic)” directive after “pragma omp parallel for.” The reason for the speed reduction is that the for directive ensures that the regular “for” directive by default calls schedule(static), where the matrix is partitioned and iterated by a different “team” of threads [3], close to one another. However, in this example, the directive “schedule(dynamic)” allows the matrix to be iterated over in any order. This means, sometimes the times can be awful, other times it can work as good or better then the static version. E.g. I ran this program five separate times and the times varied from 4.08512 – 0.98526.
A programmer can use this to their advantage, such as the example below (which uses the standard for without schedule(dynamic):
This example, titled Poor OpenMP for Loop is still not exactly what we are looking for, but will on average be far superior to our thrashing examples. Further, this poor implementation will only beat out similar cache optimizations for large matrices (above 16384 x 16384) due to the overhead of creating the parallel processes. In other words, although this is the best OpenMP example we have seen thus far, it still only slightly beats out the cache optimized examples for larger matrices and is actually slower for smaller matrices [4].
Finally, we arrive at the proper use of OpenMP. This takes advantage of all that we have seen, although there it is being parallelized on the outer loop there is little to no thrashing because each of the threads will likely run on different processors. This means that each iteration of variable ‘x’ will require a new row to be loaded into the L1 Cache, but since each processor has it’s own L1 Cache this is fine.
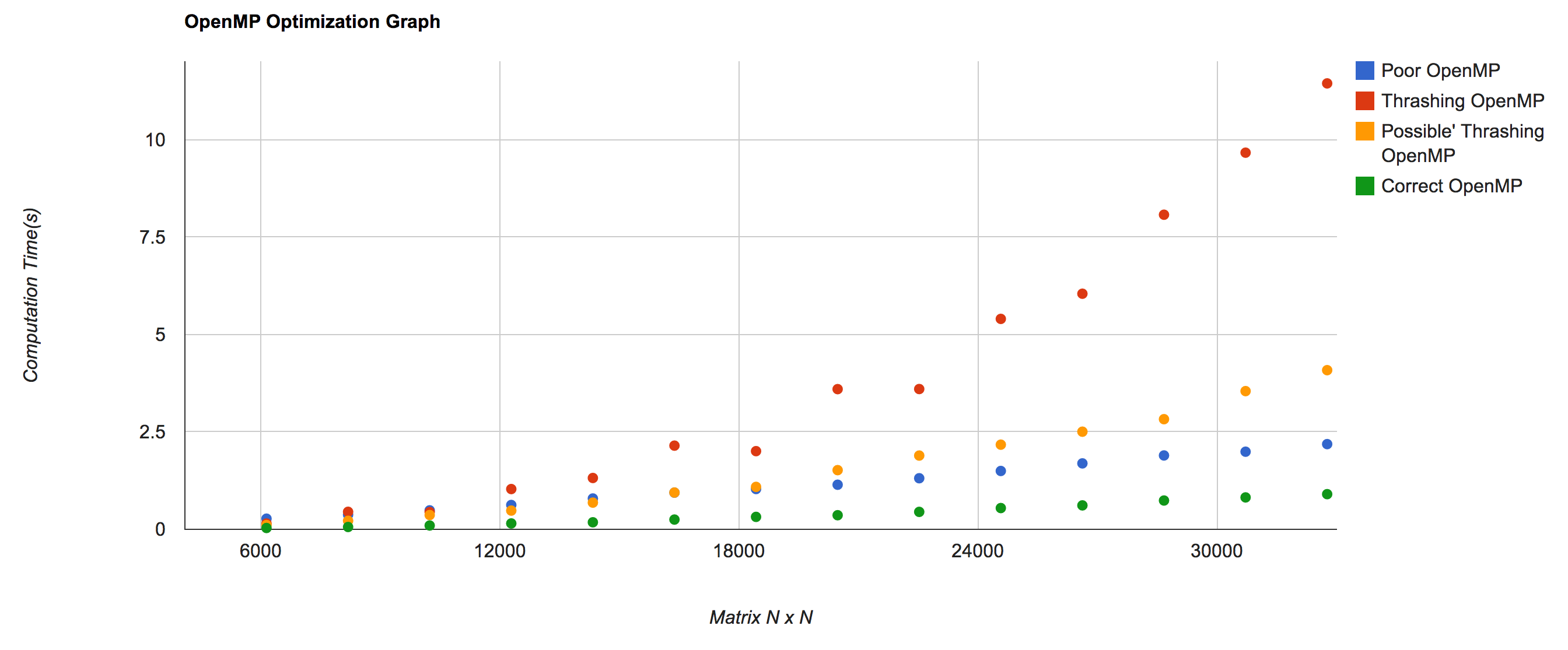
Now although the graph makes it seem as if the poor and proper implementation of OpenMp are similar this is not the case, here is the brake down:
| Matrix Size | Poor OpenMP | Thrashing OpenMP | Possible’ Thrashing OpenMP | Correct OpenMP |
| 32768 | 2.18713 | 11.4459 | 4.08512 | 0.902855 |
| 30720 | 1.99248 | 9.66737 | 3.54753 | 0.819127 |
| 28672 | 1.89593 | 8.07492 | 2.8273 | 0.739308 |
| 26624 | 1.69256 | 6.04724 | 2.50618 | 0.614316 |
| 24576 | 1.49792 | 5.40121 | 2.17297 | 0.545848 |
| 22528 | 1.31109 | 3.60082 | 1.89319 | 0.448051 |
| 20480 | 1.14486 | 3.59833 | 1.51916 | 0.362095 |
| 18432 | 1.03445 | 2.00674 | 1.08968 | 0.319583 |
| 16384 | 0.941509 | 2.14807 | 0.943847 | 0.250598 |
| 14336 | 0.791593 | 1.3178 | 0.68556 | 0.180827 |
| 12288 | 0.624828 | 1.03365 | 0.480829 | 0.151223 |
| 10240 | 0.487268 | 0.442798 | 0.3672 | 0.0979596 |
| 8192 | 0.374512 | 0.450326 | 0.219623 | 0.0600904 |
| 6144 | 0.273922 | 0.147765 | 0.109488 | 0.0345248 |
| 4096 | 0.175434 | 0.061479 | 0.0449684 | 0.0161064 |
And in comparison with caches (abridged list, full graph) [4]:
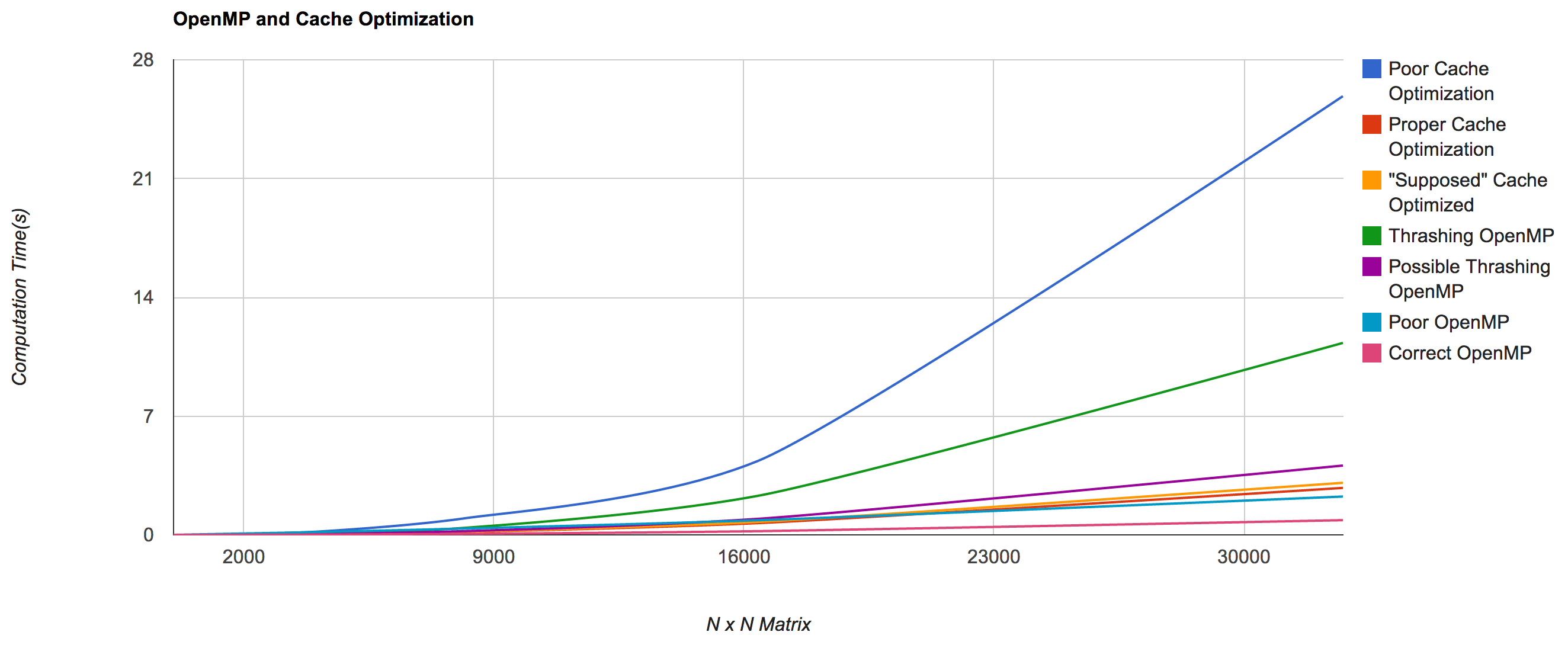
and a close up for better comparison:
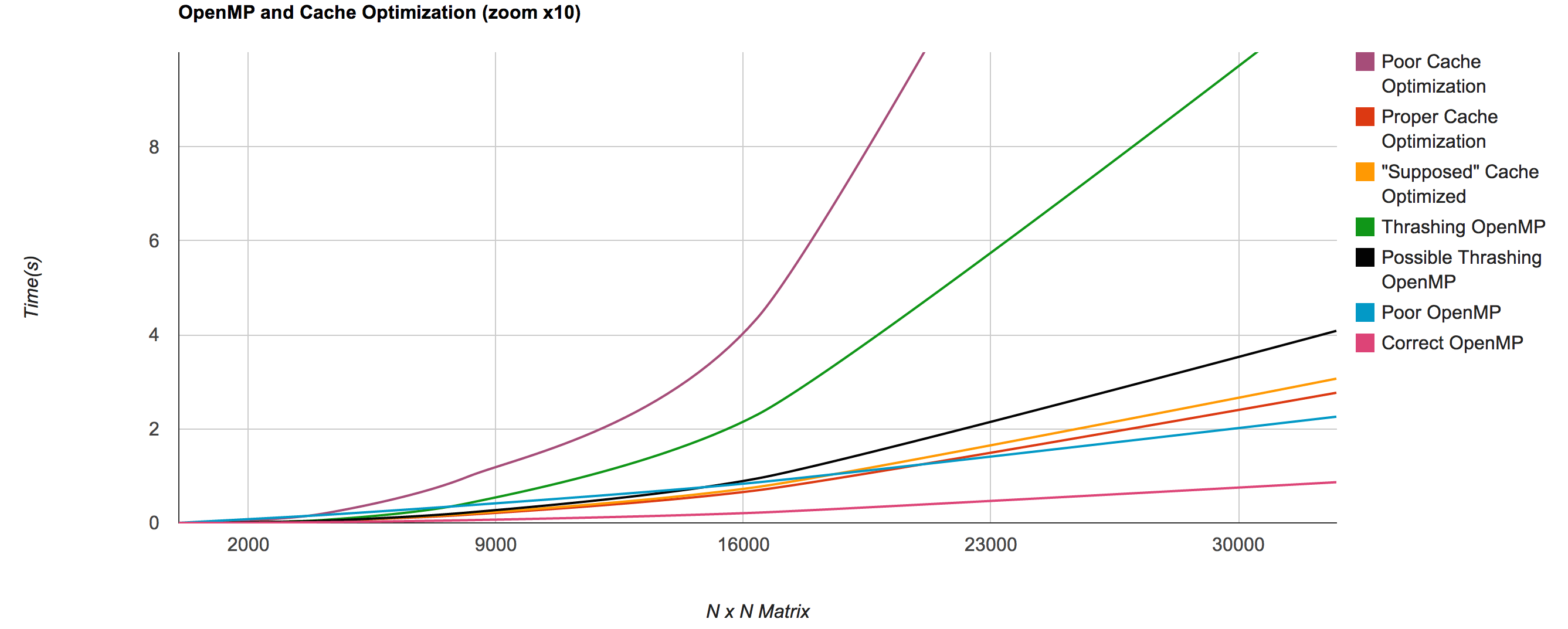
| Matrix Size | Poor Cache Optimization | Proper Cache Optimization | Thrashing OpenMP | Correct OpenMP |
| 32768 | 25.8573 | 2.76786 | 11.3137 | 0.865445 |
| 16384 | 4.35095 | 0.692579 | 2.2987 | 0.217925 |
| 8192 | 0.978711 | 0.174101 | 0.415764 | 0.0574632 |
| 4096 | 0.195106 | 0.0427591 | 0.0609522 | 0.0152688 |
| 2048 | 0.050167 | 0.010645 | 0.0141709 | 0.00353317 |
| 1024 | 0.00781927 | 0.00268598 | 0.00258317 | 0.000945854 |
| 512 | 0.00134602 | 0.000734997 | 0.000518513 | 0.000358009 |
| 256 | 0.000237608 | 0.000176191 | 0.000171041 | 0.000106621 |
| 128 | 5.22E-05 | 4.42E-05 | 0.000112438 | 4.98E-05 |
| 64 | 1.29E-05 | 1.14E-05 | 6.64E-05 | 4.54E-05 |
| 32 | 3.62E-06 | 3.00E-06 | 4.23E-05 | 4.61E-05 |
Data and Program:
Related
- Virtual Memory and You – How memory is actually stored/retrieved.
- Turkey Dinners and Cache Conscious Programming – How to program in order to optimize cache usage.
- Presentation
If you’re looking for more write-up material or just to dive deeper into some of this stuff, try Ulrich Drepper’s What Every Programmer Should Know About Memory — if you haven’t already read it — and the problems which can be solved efficiently by a parallel computer are those in NC.
Your example is bogus – consider just “possible_” vs. “good_”.
In the possible_ function, you use “#pragma omp parallel”, while in the good_ function, you use “#pragma omp parallel for”. The former implies that every OpenMP thread will execute every iteration of the for loop, while the latter implies the compiler will split up the work to share amongst the threads.
This means the major effect is that you’re duplicating work (e.g., 4x with 4 threads) as opposed to _distributing_ work (e.g., each thread does 1/4 the work).
The performance you’re measuring is not cache related, it’s work distribution and duplication.
That was my mistake, I am not too familiar with OpenMP.
I changed possible thrash to be using:
#pragma omp parallel for schedule(dynamic)
I updated github and the results.
Thanks for pointing that out, I’m less familiar with OpenMP than other threading libraries.
Hello,
I did a similar test in C and have gotten very similar results. When N is around 4000 the trashing version starts to differ substantially. A 3x difference can already be seen when N is 1000.
*This means if your program is running on two threads over different parts of the matrix, every single iteration requires a request to RAM.*
I’m skeptical over this part, I have tried to replicate this behavior but was unsuccessful. Even though cores are sharing L3, I doubt that a thread will overwrite the entire cache on every iteration.
Different compilers and architecture will have different results. Either way, you should see a noticeable difference as the size increases, which was the point.
In your example “Poor OpenMP for Loop you’re spawning and killing OpenMP threads in each of the outer iterations.
To avoid this split your pragmas into two parts. One pragma outside the outher loop that spawns the threads, and one pragma before the inner loop that parallelizes the inner loop among the threads.
Instead of making an array of arrays, you could gain a extra performance by allocating a one dimensional array of quadratic size.
This ensures that the entire array is allocated in one contiguous memory chunk.
Even though the branch predictor could remove a lot of the overhead from introducing a conditional inside a loop, it was faster to split the outer loop into two parts.
double my_attempt(unsigned int * matrix, const long unsigned int size){
const double total_begin = omp_get_wtime();
#pragma omp parallel
{
#pragma omp for
for(size_t x = 0; x < size-1; x++){
__builtin_prefetch(&(matrix[x+1]));
for(size_t y = 0; y < size; y++){
matrix[x*size+y] *= 2;
}
}
#pragma omp for
for(size_t y = 0; y < size; y++){
matrix[(size-1)*size+y] *= 2;
}
}
const double total_end = omp_get_wtime();
return double(total_end – total_begin);
}
My benchmarks for my best attempt.
It should be noticed that I changed the makefile to include -O3 and I changed the number of iterations for each function to 50 to warm up my cpu.
Size=16384
Poor OpenMP 0.198578
'Possible' Thrashing OpenMP: 0.132157
Correct OpenMP 0.132819
my_attempt 0.126265 4,66% faster than " 'Possible' Thrashing OpenMP"