
This is the fourth article in an eight part series on a practical guide to using neural networks, applied to real world problems.
Specifically, a problem we faced at Metacortex. We needed our bots to understand when a question, statement, or command sent to our bot(s). The goal being to query the institutional knowledge base to provide answers.
This particular article is regarding a basic neural network design (Multilayer Perceptron) to classify sentence types.
What this guide covers:
- Acquiring & formatting data for deep learning applications
- Word embedding and data splitting
- Bag-of-words to classify sentence types (Dictionary)
- Classify sentences via a multilayer perceptron (MLP)
- Classify sentences via a recurrent neural network (LSTM)
- Convolutional neural networks to classify sentences (CNN)
- FastText for sentence classification (FastText)
- Hyperparameter tuning for sentence classification
Introduction to Neural Networks
There many different architectures to neural networks, meaning they have a different design. You can think of them as different algorithms. Each neural network design has its strengths, weaknesses, run-time, memory complexity, etc. In this article, we will be covering one of the basic architectures.
So, how does a neural network classify a sentence?
To clarify how neural networks do classification, we first have to understand the way a neural networks computes data (please, bare with me).
In short, a neural network contains…
- A series of layers that consist of nodes and directed edges consisting of weights connecting node(s) between layers
- Each layer is calculated by taking the value of the nodes in a prior layer, then applying weights
- Once the weights are applied, the value is passed along where edges directs (to a node), most nodes will have several input weights
- Every node then applies an activation function to the input series of weights, creating a singular value for the given node
- After the values in all the nodes (in a layer) have been calculated, the process repeats with the next set of weights
For more discussion on activation functions, I recommend the wikipedia page
Importantly, this design is computationally solving something similar to a Taylor Series, in that virtually any arbitrary function can then be learned and represented as a neural network.
I understand that may have been confusing, so there’s a real example in the next section — hang in there.
Next, how does training work?
Training a neural network consists of identifying the weights to be applied between each layer / node.
Optimizer (finding appropriate weights)
The goal of training a neural network is identifying weights that solve the desired goal.
Identifying weights is accomplished via calculating the backward propagation of errors (backpropagation for short). Essentially, every time the network checks how accurate the results are, the weights are updated via Gradient Decent, Adaptive Moment Estimation (Adam), or any other number of optimization algorithms. There’s a decent description of several optimizers (optimization algorithms) on this Towards Data Science post.
Optimizers by themselves don’t do much, they also need a defined “loss function.” A loss function is a mapping of an output to “cost” for getting something wrong, i.e. a way to represent failure. There’s a list of loss functions in Keras, but we’ll be using categorical cross entropy for all our neural networks in this guide, and we’ll be “optimizing” over accuracy, i.e. trying to improve the accuracy of sentence type classification of our model.
Epochs, Batch Size, Iterations
In addition, to domain specific neural network terminology, we also need to understand some general machine learning terms.
From, Stack Overflow:
- Epoch – one forward pass and one backward pass of all the training examples
- Batch Size – The number of training examples in one forward/backward pass. The higher the batch size, the more memory space you’ll need.
- Iterations – number of passes, each pass using [batch size] number of examples (one forward pass + one backward pass)
Multilayer Perceptron (MLP)
Below is a design of the basic neural network we will be using, it’s called a Multilayer Perceptron (MLP for short).
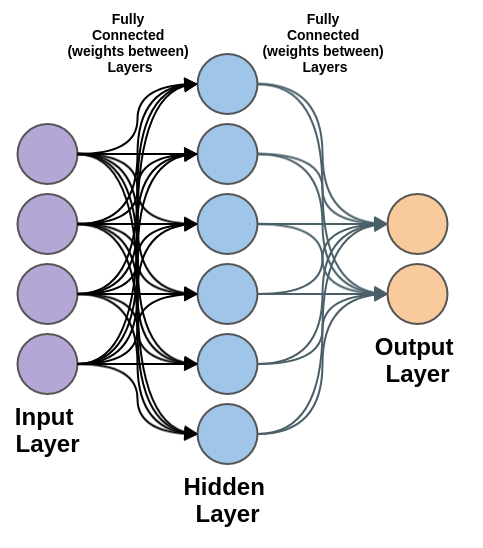
Certainly, Multilayer Perceptrons have a complex sounding name. However, they are considered one of the most basic neural networks, their design being:
- Input layer – layer “I”
- Hidden layer(s) – layer “H“
- Output layer – layer “O“
The layers are then fully connected in a chronological way (input to output), typically referred to as feedforward: input -> hidden -> output.
Each layer is fully connected by a set of weights:
“W1” fully connects I to H
“W2” fully connects H to O
W1 and W2 are fully connected, meaning each node of I is connected to every node of H.
Classify Sentence Type using a Neural Network (MLP)
Finally, we get to our specific use case (classifying sentence types)!
Our network, will use the following configuration:
- Input Layer (I)
- Size: Max words (set to 10000 unique words + POS + punctuation)
- Hidden Layer (H)
- Size: 500
- Activation Function: Tanh
- Dropout: 0.5 – reduces risk of over fitting (i.e. trains well on training data, fails on test data)
- Output Layer (O)
- Size: 3 (Sentence Types, three categories: statement, question, command)
- Activation Function Softmax
- Optimizer: Adaptive Moment Estimation (Adam)
- Loss Function: Categorical Cross Entropy for the loss function (used for the optimizer)
- Optimizing on: Accuracy
In terms of Python(3.6+) & Keras (2.2.4) code:
The above code both constructed the network and evaluates the accuracy. Keras uses a type of short hand to describe the networks, which make it very easy to use, understand and maintain. The code accurately matches to the previous image, shown as an example of an MLP network.
Data Input Formatting
Unfortunately, designing the neural network is only half of it. Another major consideration is formatting the data into the network.
The primary method is mapping each word into a binary vector, where each word is represented by an index in the binary vector. By default all the values of the binary vector are zero and the index that represents the word is one. As every word is represented by a vector, a comment is a vector of vectors.
Input Format
In other words:
- We take all of the words mentioned in our training / testing data
- Rank the most common words by usage
- Take the top X words by usage
- Create a binary vector for each word of X length, with a default value of zero
- Assign a word to each index of the vector
- Map each word to the appropriate index, such that there is only one non-default value in each vector
This leaves us with each sample comment looking like:
[
[ 1, 0, …., 0, 0, 0, …., 0, 0 ],
[ 0, 0, …., 0, 1, 0, …., 0, 0 ],
[ 0, 1, …., 0, 0, 0, …., 0, 0 ],
….,
[ 1, 0, …., 0, 0, 0, …., 0, 0 ],
[ 1, 0, …., 0, 0, 0, …., 0, 0 ],
[ 0, 0, …., 0, 1, 0, …., 0, 0 ]]
For example, in Python + Keras it would look something like the following (building off our previous post for the “load_encoded_data“ function):
Once the input is formatted as a series of matrices, we can use it as input(s) to our neural network.
Output Format
Additionally, the output also needs a to be in a vector format. Our output is an attempt to classify a sentence type into a category, so we must convert all the outputs into a categorical.
In Keras, that means converting the categories to a similar form as the input:
- We take all possible categories mentioned in our training / testing data
- Determine possible categories in Y (add one, for none)
- Create a binary vector for each word of Y length, with a default value of zero
- Assign a category to each index of the vector
- Map each category to the appropriate index, such that there is only one non-default value in each vector
In terms of what the coding looks like, it’s also very similar (except we use a function from Keras utils called to_categorical):
Multilayer Perceptron to Classify Sentence Types
Finally, we stitch the previous pieces together and set our parameters:
- max_words = 10,000
- batch_size = 256
- epochs = 3
If we run the code, along with our testing data (which you can do from the github repo),
The MLP accurately classifies ~95.5% of sentence types, on the withheld test dataset.
Overall, that’s an approximate 10% improvement in accuracy of classification, over our baseline keyword search solution. Not bad!
What’s also important is speed, mostly of classification, but also of training. I have the following computer configuration:
- RAM – 32 Gb DDR4 (2400)
- CPU – AMD Ryzen 7 1800x eight-core processor × 16
- GPU – GTX 1080
- OS – Arch Linux
Speed (per step):
The model can train at 61 μs/step and classify at 41 μs/step (μs – microsecond)
Up Next…
The of accuracy and speed of the MLP be good enough for some applications. However, from my experience, humans typically expect a >99% accuracy for bots they interact with.
If 5% of the time your bot did not understand a question was being asked, it would ruin immersion. As a result, we will continue in our next section in an attempt to further improve our accuracy.
The next article will cover Recurrent Neural Networks (RNN) using LSTM cells.
Full Guide:
- Acquiring & formatting data for deep learning applications
- Word embedding and data splitting
- Bag-of-words to classify sentence types (Dictionary)
- Classify sentences via a multilayer perceptron (MLP)
- Classify sentences via a recurrent neural network (LSTM) (Next Article)
- Convolutional neural networks to classify sentences (CNN)
- FastText for sentence classification (FastText)
- Hyperparameter tuning for sentence classification