
This is the fifth article in an eight part series on a practical guide to using neural networks to, applied to real world problems.
Specifically, this is a problem we faced at Metacortex. We needed our bots to understand when a question, statement, or command sent to our bot(s). The goal being to query the institutional knowledge base to provide answers.
This article covers designing a recurrent neural network to classify sentence types:
- Statement (Declarative Sentence)
- Question (Interrogative Sentence)
- Exclamation (Exclamatory Sentence)
- Command (Imperative Sentence)
Full Guide:
- Acquiring & formatting data for deep learning applications
- Word embedding and data splitting
- Bag-of-words to classify sentence types (Dictionary)
- Classify sentences via a multilayer perceptrons (MLP)
- Classify sentences via a recurrent neural network (LSTM)
- Convolutional neural networks to classify sentences (CNN)
- FastText for sentence classification (FastText)
- Hyperparameter tuning for sentence classification
Introduction to Recurrent Neural Networks (RNNs)
Recurrent neural networks (RNN) are robust networks which have a memory of prior inputs. This enables RNNs to have improved accuracy compared to MLPs, which only have the single input and no memory, RNNs can take several prior input and extrapolate out with improved accuracy. In other words, RNNs take into consideration what it has learned from prior inputs to classify the current input.
RNNs are particularly useful when there is a sequence of data which has a time series component (as opposed to a spatial component).
In terms of design, we can look back at the multilayer perceptron (MLP) or the most basic feed-forward neural network. The design is simple because the layers of the neural network are fully connected and one layer “feeds” into the next:
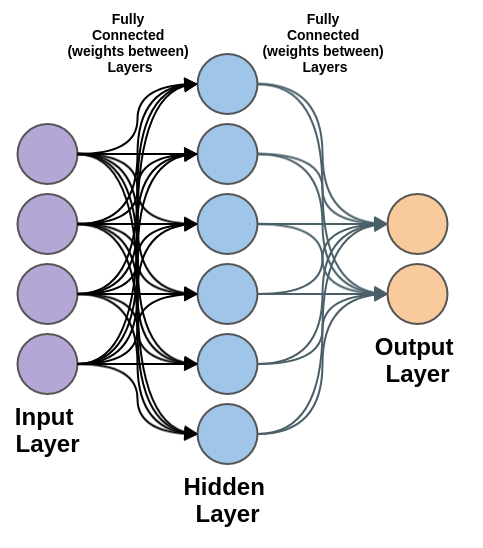
In contrast, a Recurrent Neural Network (RNN) has a feedback mechanism at the recurrent layers. Our first example will be short-term memory, as opposed to long short-term memory (LSTM), which we will cover in a later section:
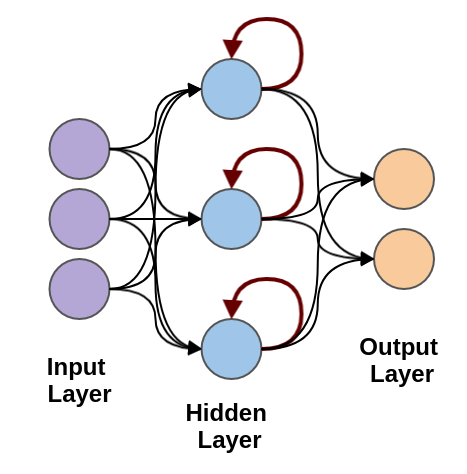
Note, the maroon arrows feeding back into the nodes of the hidden layer. This could also be classified as the “recurrent layer” of the neural network. It is also possible to have a combination of layers of different types (for instance recurrent and fully connected, feed-forward layers):
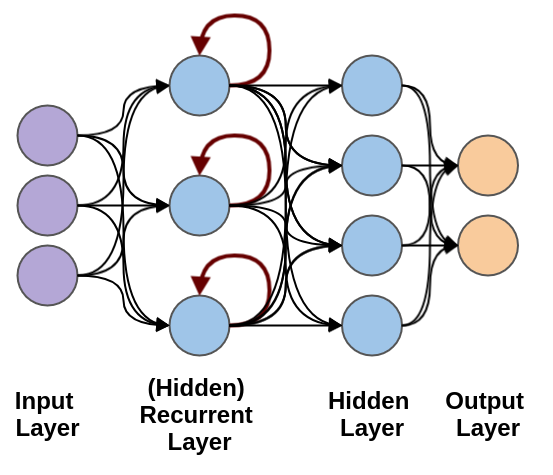
What’s particularly powerful about this recurrent layer, is that it’s possible to map a one-to-many and many-to-many relationship(s), as individual inputs are fed in, the sequence of events are captured in the state of the recurrent layer.
There’s a lot more that go into Recurrent Neural Networks (RNN) that could be covered, but that’s the gist.
Long Short-Term Memory Units (LSTMs)
One particular aspect of Recurrent Neural Networks (RNN) we have yet to cover here is vanishing and exploding gradients and unfortunately we don’t have time to. If you have time, I recommend reading about it in some supplemental material. The main reason we aren’t diving into too much detail on the vanishing and exploding gradients problem, is because LSTMs solve this issue (to a large extent).
The general idea:
Long short-term memory (LSTM) prevents backpropagated errors from vanishing or exploding. I nstead, errors can flow backwards through unlimited numbers of virtual layers unfolded in space. That is, LSTM can learn tasks that require memories of events that happened thousands or even millions of discrete time steps earlier. LSTM works even given long delays between significant events and can handle signals that mix low and high frequency components.
In terms of what that looks like (also from Wikipedia):

If you don’t understand, that’s alright. The above is using the de-facto standard notation for neural networks, which is difficult to understand without having some context.
Instead of trying to explain further — in my own words:
LSTM cells are trained to remember what they need to and forget what they don’t.
Sure, it’s a bit over simplified, but it’s all you need to understand for the moment. We create an LSTM layer where we’d normally use a vanilla recurrent layer and we can improve our neural network – pretty much all you need to know to get started (although I highly recommend reading more, after finishing this article).
Classify Sentence Types using a Recurrent Neural Network (LSTM)
To the point, our recurrent neural network will use the following configuration:
- Input Layer (I)
- Size: Max words (set to 10000 unique words + POS + punctuation)
- Padding: required
- LSTM Layer (H)
- Size: 128
- Dropout: 0.2 – reduces risk of over fitting (i.e. trains well on training data, fails on test data)
- Output Layer (O)
- Size: 3 (Sentence Types, three categories: statement, question, command)
- Activation Function Softmax
- Optimizer: Adaptive Moment Estimation (Adam)
- Loss Function: Categorical Cross Entropy for the loss function (used for the optimizer)
- Optimizing on: Accuracy
In terms of Python (3.6+), TensorFlow (1.12), & Keras (2.2.4)
code:
Overall, it’s not more complex to code than the basic Multilayer Perceptron (MLP), from the prior section.
Data Input Formatting
We use the almost the exact same data formatting from the prior section as well! The only change being that we should “pad” our input to ensure the length of the input vector is consistent. In other words we do:
Original Input Vector: [ 0, 1, 3, 5, 9, 4, 0 ]
Desired Input Size: 500
Padded Input Vector: [ 0, 1, 3, 5, 9, 4, 0, …, 0 ]** We pad the input vector with 0’s until desired input size is met
This is mostly to avoid confusion of having input vectors of different lengths and simplifies the input method(s). Specifically, at the time of writing, it is simply easier to pad the vectors prior to input when using Keras. Although, there are alternative methods for handling variable length input vectors to RNNs.
That’s it! With the code above (using functions from previous sections) we can get the data formatted.
It’s important to note, given the current setup, keep maxlen to be as short as possible. With padding, remember all input will be set to that exact length — if a high value is selected it will dramatically slow down training and classification; as well as increasing the memory requirements.
Recurrent Neural Network (LSTM) to Classify Sentence Types
Finally, we can construct everything together and set the hyperparameters:
- max_words = 10,000
- batch_size = 125
- maxlen = 500
- epochs = 5
If we run the code, along with our testing data (which you can do from the github repo),
The RNN accurately classifies ~98.5% of sentence types, on the withheld test dataset.
Overall, that’s a 3% improvement in accuracy of classification over MLP method and a 13% improvement in accuracy, over our baseline keyword search solution.
That’s close to what I would expect from a human in performance.
In fact, below are examples. The model was able to classify these sentences with 100% accuracy, can you?
“This is a stupid example.” – Statement
“This is another statement, perhaps this will trick the network” – Statement
“I don’t understand” – Statement
“What’s up?” – Question
“open the app” – Command
“This is another example” – Statement
“Do what I tell you” – Command
“come over here and listen” – Command
“how do you know what to look for” – Question
“Remember how good the concert was?” – Question
“Who is the greatest basketball player of all time?” – Question
“Eat your cereal.” – Command
“Usually the prior sentence is not classified properly.” – Statement
“Don’t forget about your homework!” – Command
What’s also important is speed, mostly of classification, but also of training. I have the following computer configuration:
- RAM – 32 Gb DDR4 (2400)
- CPU – AMD Ryzen 7 1800x eight-core processor × 16
- GPU – GTX 1080
- OS – Arch Linux
Speed (per step):
The model can train at 7 ms/step and classify at 1 ms/step (μs – microsecond, ms – millisecond)
In other words, the RNN is 42x slower than the MLP approach.
Up Next…
Although our first attempt at an RNN was able to get very near 99% accuracy, it is way way to slow for our system. Although 1ms response time from a model seems acceptable, when you process hundreds to thousands of comments a second, it is totally unacceptable for our application(s). That would significantly increase our costs to hose the model.
At the same time, the MLP neural network architecture was too inaccurate to be as effective as desired.
The next article will cover Convolutional Neural Networks (CNN), which are often as accurate as RNNs, but also nearly as fast as MLPs.
Full Guide:
- Acquiring & formatting data for deep learning applications
- Word embedding and data splitting
- Bag-of-words to classify sentence types (Dictionary)
- Classify sentences via a multilayer perceptrons (MLP)
- Classify sentences via a recurrent neural network (LSTM)
- Convolutional neural networks to classify sentences (CNN) (Next Article)
- FastText for sentence classification (FastText)
- Hyperparameter tuning for sentence classification