
This is the seventh article in an eight part series on a practical guide to using neural networks, applied to real world problems.
Specifically, this is a problem we faced at Metacortex — where we needed our bots to understand when a question, statement, or command sent to our bot(s). The goal being to query the institutional knowledge base to provide answers.
This article covers applying the FastText algorithm sentence type classification (statement, question, command).
Full Guide:
- Acquiring & formatting data for deep learning applications
- Word embedding and data splitting
- Bag-of-words to classify sentence types (Dictionary)
- Classify sentences via a multilayer perceptron (MLP)
- Classify sentences via a recurrent neural network (LSTM)
- Convolutional neural networks to classify sentences (CNN)
- FastText for Sentence Classification (FastText)
- Hyperparameter tuning for sentence classification
Introduction to FastText
FastText is an algorithm developed by Facebook Research, designed to extend word2vec (word embedding) to use n-grams. This improves accuracy of NLP related tasks, while maintaining speed. An n-gram represents N words prior to the current word to create a single phrase. This provides context to the input similar to the way the RNN interprets the time series aspect and the CNN encodes the spatial aspect of the data.
For example:
Sentence: This is a test phrase.
1-Gram (Unigram): [ This, is, a, test, phrase, . ]
2-Gram (Bigram): [ This is, is a, a test, test phrase, phrase. ]
3-Gram (Trigram): [This is a, is a test, a test phrase, test phrase. ]
To clarify, we are using word embeddings as opposed to character embeddings.
Character embeddings for the above would look something like this:
Sentence: This is a test phrase.
3-Gram (Trigram): [ This, his, is i, s is, s a, a t, a te, tes, test, est, st p, t ph, phr, phra, hras, rase, ase, se ., e . , . ]
Using character n-grams can create a more robust network as partial components of words are often shared. However, for our case, we use a combination of words and punctuation, leaving out the parts-of-speech and not using characters.
After, the n-grams have been created, the features are then averaged (pooling) and send to the hidden variables. Then we apply a softmax activation function to the output, that’s it!
In terms of an architecture, it’s relatively simple:
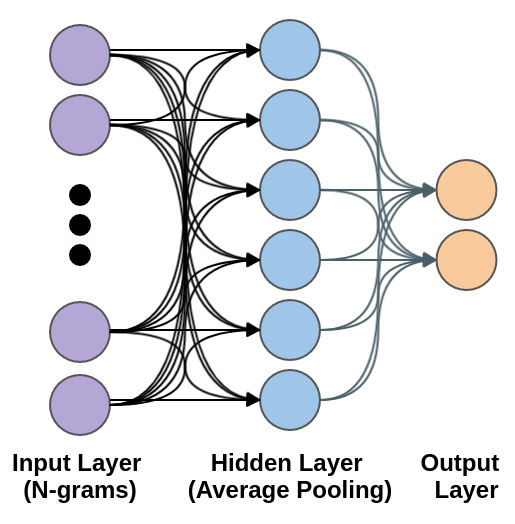
The only change to a standard Multilayer Perceptron (MLP) is using the n-grams as the input and the average pooling for the next layer.
For further reading, I recommend the original publication: Bag of Tricks for Efficient Text Classification
Classify Sentence Types with a FastText
With the understanding of what FastText is, our configuration:
- Input Layer (I)
- Size: Max words (set to 10000 unique words + punctuation)
- n-grams (bigrams)
- Hidden Layer(s) (H)
- Average pooling
- Output Layer (O)
- Size: 3 (Sentence Types, three categories: statement, question, command)
- Activation Function Softmax
- Optimizer: Adaptive Moment Estimation (Adam)
- Loss Function: Categorical Cross Entropy for the loss function (used for the optimizer)
- Optimizing on: Accuracy
In terms of Python (3.6+) & Keras (2.2.4) code:
Data Input Formatting
The key to FastText is the n-gram creation, so as you may have guessed quite a bit of data formatting is required. Luckily, the idea behind n-grams are fairly well known and even used in common databases such as PostgreSQL (which has built-in trigram searching).
In terms of the n-gram creation, I ended up using the examples from the Keras repository:
With the n-gram creation functions, creating the n-grams for the training / testing data is possible. We first convert the output values to categories, then we convert the embedded input words + punctuation into n-grams (bi-grams in our case). Once we have bi-grams we pad the rest of the values and we are good to go:
There’s a couple of caveats with FastText at this point — compared to the other models, its relatively memory intensive. This is especially true, as the n-grams size increases it will increase the memory usage significantly (uni-gram to bi-gram is 2x the memory). In addition, padding is dictected by maxlen and should be as short as practical. A high amount of padding will dramatically slow down training and classification and increase the memory requirements.
FastText to Classify Sentence Types
With data formatting complete, we can assemble the final components.
We will be using the following hyperparameters:
- ngram_range = 2
- max_words = 10000
- maxlen = 500
- batch_size = 32
- embedding_dims = 50
- epochs = 5
If we run the code, along with our testing data (which you can do from the github repo):
The FastText accurately classifies ~95.59% of sentence types, on the withheld test dataset.
Overall, that’s:
- A 3% reduction in accuracy of classification compared with the RNN
- A 2% reduction in accuracy of classification compared with CNN
- A 1% reduction in accuracy of classification compared with MLP
- A 10% improvement in accuracy, over our baseline keyword search solution
What’s also important is speed, mostly of classification, but also of training. I have the following computer configuration:
- RAM – 32 Gb DDR4 (2400)
- CPU – AMD Ryzen 7 1800x eight-core processor × 16
- GPU – GTX 1080
- OS – Arch Linux
Speed (per step):
The model can train at 196 μs/step and classify at 26 μs/step (μs – microsecond, ms – millisecond)
In comparison, FastText is:
- 38x faster than the RNN
- 2x faster than MLP
- 1.3x faster than CNN
That makes FastText the fastest model; the dictionary check is still the fastest, but horrible accuracy.
Up Next…
The next article in the series is a comparison of the models and a brief introduction to hyperparameter tuning.
Full Guide:
- Acquiring & formatting data for deep learning applications
- Word embedding and data splitting
- Bag-of-words to classify sentence types (Dictionary)
- Classify sentences via a multilayer perceptron (MLP)
- Classify sentences via a recurrent neural network (LSTM)
- Convolutional neural networks to classify sentences (CNN)
- FastText for Sentence Classification (FastText)
- Hyperparameter tuning for sentence classification (Next Article)
Hi Austin,
Nice post! I have a question. Usually, when I have implemented a text classifier before, as a first step I’ve trained an embedding algorithm with a corpus (w2v, ft, glove… whatever), then insert it to the keras embedding layer passing the weights matrix as an input argument, and turning the trainable parameter to False, in order to leave embedding weights as they were learned by the native algorithm.
In this case no weights are passed as argument, so the layer takes a random initialization. This is also the way that FacebookResearch use in its own FastText Classifier?
I hesitated about the n-gram meaning because in unsupervised fasttext denotes subword chunks, but as I can see either in your post or in the official site, when talking about the classifier n-gram, it denotes groups of words.
It means that the fasttext classifier does not take into account the subword level?
Hope you can clarify me these doubts.
Thanks in advance!
This fasttext model does not take into account subwords as it uses word level embeddings.
In this case, we are creating our own encoding, such that each word is represented by a single value. This would make it impossible to use n-grams on subparts of words[1]. However, n-grams can refer to n-words, n-characters, or even n-sentences. For the guide the “gram” represents “words and/or punctuation”. You could attempt to convert the code to one-hot encode at the character level as well, and then the “gram” in “n-grams” would be representing n-characters.
[1] https://austingwalters.com/word-embedding-and-data-splitting/
Ok, understood.
Thank you again 🙂