
This is the sixth article in an eight part series on a practical guide to using neural networks, applied to real world problems.
Specifically, this is a problem we faced at Metacortex. We needed our bots to understand when a question, statement, or command sent to our bot(s). The goal being to query the institutional knowledge base to provide answers.
This article covers designing a convolutional neural network to classify sentence types.
Full Guide:
- Acquiring & formatting data for deep learning applications
- Word embedding and data splitting
- Bag-of-words to classify sentence types (Dictionary)
- Classify sentences via a multilayer perceptron (MLP)
- Classify sentences via a recurrent neural network (LSTM)
- Convolutional neural networks to classify sentences (CNN)
- FastText for sentence classification (FastText)
- Hyperparameter tuning for sentence classification
Introduction to Convolutional Neural Networks (CNNs)
Convolutional Neural Networks (CNN) were originally designed for image recognition[1], and indeed are very good at the task. They use a variation of Multilayer Perceptrons (MLP), with improvements made for matrices (as opposed to vectors) and pooling. In other words, we should expect them to perform both better in terms of accuracy and equivalent in speed to the MLP approach — exactly what we are looking for!
In terms of architecture, you can expect a CNN to have the following:
- Input Layer (I)
- Padding: required
- Hidden Layer(s) (H)
- Convolutional layer(s) <– we’ll get to that
- Activation Function: RELU
- Pooling Layer(s)
- Fully connected Layer(s)
- Normalization layer(s)
- Output Layer (O)
Immediately, you may notice all those hidden layer(s) components. Those are what work the magic and a lot of the ideas from image processing, though the technique can be applied generally (including to sentence classification).
Convolutional Layers
The goal of the convolutional layer is to extract features from an input.
Essentially, a convolutional layer is applying a filter to the input. Leaving, only the desired values (or combination of values) to be passed to the next layer. This is actually a very well known method of applying filters and is used regularly in computer vision for edge detection.
Below is an example of a filter (also referred to as a kernel and feature detector) and an input (image) matrix:
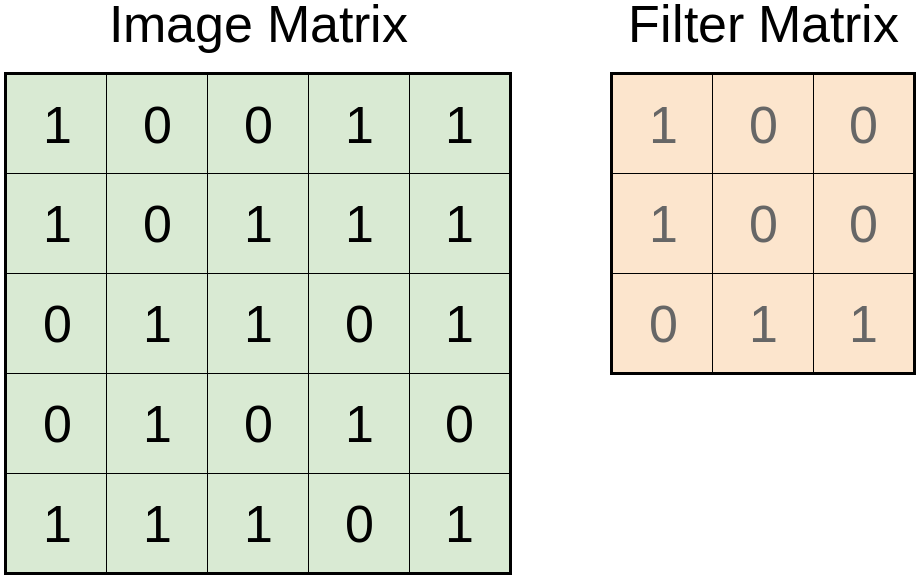
The filter matrix will then be applied over the image matrix, producing a convolved feature matrix:
 This is exactly how your phone applies edge detection, Gaussian blur, sharpen, etc. — I cover this in my article on edge detection, but these filters can dramatically improve other algorithms and work similar to the way our eyes interpret the world.
This is exactly how your phone applies edge detection, Gaussian blur, sharpen, etc. — I cover this in my article on edge detection, but these filters can dramatically improve other algorithms and work similar to the way our eyes interpret the world.
Pooling Layers
Pooling is also an important aspect of Convolutional Neural Networks (CNN), as they reduce the number of input parameters and make computation faster (and often more accurate). The goal is to segment the input matrix / vector and reduce the dimensions by pooling the values. A
There are four different ways to do pooling (that I know of):
- Max Pooling – Select maximum value in the section
- Min Pooling – Select minimum value in the section
- Average Pooling – Average all values in the section
- Sum Pooling – Summing all values in the section
Below is an example of max pooling (what we will be using) of a 4×4 matrix to a 2×2 max pooled matrix:
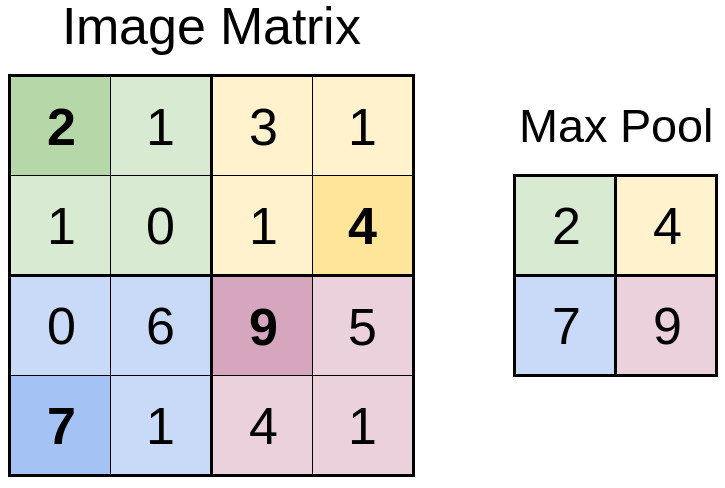 Upon inspection the darker, bold numbers in each colored section appear in “max pool”, as they are the largest values in the respective colored sections. The image above is max pooling with a 2×2 filter, similar to the convolutional layer, but no mask is being applied. The same can be applied to a 3×3, 5×5 filter, etc.
Upon inspection the darker, bold numbers in each colored section appear in “max pool”, as they are the largest values in the respective colored sections. The image above is max pooling with a 2×2 filter, similar to the convolutional layer, but no mask is being applied. The same can be applied to a 3×3, 5×5 filter, etc.
Fully Connected Layers
In short, when we think a feed-forward, fully connected basic neural network, we can think a Multilayer Perceptron (MLP). Fully-connected means the nodes of each layer fully connects to all the nodes of the next layer.
For a refresher, a MLP looks something like:
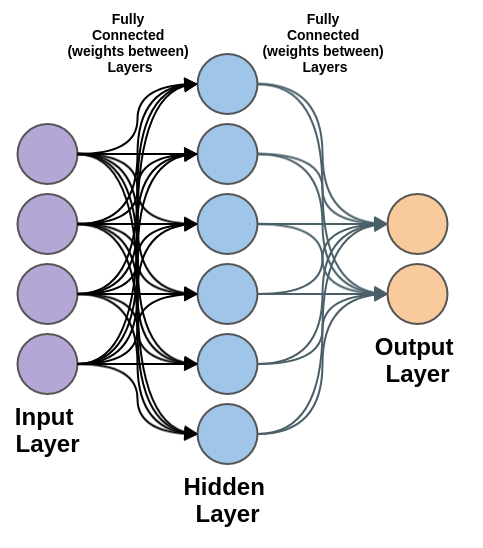
The hidden layer is both fully connected to the input layer and fully connected to the output layer.
Stride
Stride is the number of input values to shift over the input matrix. When stride is one we move one column / row at a time. When stride is three then the filter moves three columns / rows at a time.
Classify Sentence Types with a Convolutional Neural Network (CNN)
Finally, lets see how this works in action!
Our configuration:
- Input Layer (I)
- Size: Max words (set to 10000 unique words + POS + punctuation)
- Dimensions: 1-D vector of words
- Padding: required
- Hidden Layer(s) (H)
- Convolutional layer
- Dropout: 0.2 – reduces risk of over fitting (i.e. trains well on training data, fails on test data)
- Activation Function: RELU
- Pooling Layer: 1D
- Fully connected Layer
- Dropout: 0.2 – reduces risk of over fitting (i.e. trains well on training data, fails on test data)
- Activation Function: RELU
- Convolutional layer
- Output Layer (O)
- Size: 3 (Sentence Types, three categories: statement, question, command)
- Activation Function Softmax
- Optimizer: Adaptive Moment Estimation (Adam)
- Loss Function: Categorical Cross Entropy for the loss function (used for the optimizer)
- Optimizing on: Accuracy
Already, it’s clear this is quite a bit more complicated than both the MLP and RNN implementation(s).
However, in terms of Python (3.6+) & Keras (2.2.4) code, it’s fairly straight forward:
There are definitely a few more lines to account of the additional layers. However the code is not exceptionally more complex than our prior examples.
Data Input Formatting
Unfortunately, similar to the RNN we should “pad” our input to ensure the length of the input vector is consistent.
Below is an example, where we will pad the original input vector to the desired input size with zeros:
Original Input Vector: [ 0, 1, 3, 5, 9, 4, 0 ]
Desired Input Size: 500
Padded Input Vector: [ 0, 1, 3, 5, 9, 4, 0, …, 0 ]
Padding data for a CNN is nearly required, as it:
- Improves performance at the boarders of the matrix (i.e. if a feature on the edge of the input matrix is important)
- Improves robustness – Due to the convolutional and pooling layers, the dimensions should be even to be effective
Luckily, we’ve already written the code for this! It’s the exact same as what we did for the RNN:
Similar to the RNN — maxlen should be as short as practical.A high amount of padding will dramatically slow down training and classification and increase the memory requirements.
Convolutional Neural Network (CNN) to Classify Sentence Types
Finally, we can put the pieces together (data formatting and model)! It’s important there are quite a few more hyperparameters for CNNs.
We will be using the following hyperparameters:
- max_words = 10000
- maxlen = 500
- batch_size = 64
- embedding_dims = 50
- filters = 250 (size of convolved matrix)
- kernel_size = 5 (filter matrix size)
- hidden_dims = 150 (in full-connected network)
- epochs = 2
If we run the code, along with our testing data (which you can do from the github repo):
The CNN accurately classifies ~97.8% of sentence types, on the withheld test dataset.
Overall, that’s:
- A 1% reduction in performance when compared with the RNN
- A 2% improvement in accuracy of classification over MLP
- A 12% improvement in accuracy, over our baseline keyword search solution
Overall, those are some very good results, comparable with RNNs.
What’s also important is speed, mostly of classification, but also of training. I have the following computer configuration:
- RAM – 32 Gb DDR4 (2400)
- CPU – AMD Ryzen 7 1800x eight-core processor × 16
- GPU – GTX 1080
- OS – Arch Linux
Speed (per step):
The model can train at 185 μs/step and classify at 35 μs/step (μs – microsecond, ms – millisecond)
In comparison:
- The RNN is 29x slower than the CNN, and the CNN has similar accuracy
- The MLP is 2x faster than the CNN, and the CNN has 2% improved accuracy
Up Next…
The question is then, is it fast enough? The short answer is yes, the CNN will need 29x less resources to achieve roughly the same results for our sentence type classification at scale. Yes, that’s 2x more than the MLP method, but the improved accuracy would likely be worth it.
Further, with some hyperparameter tuning it should be possible to dramatically both speed up the CNN (and RNN) and improve accuracy.
In the next article we’ll be reviewing FastText, likely the fastest method we’ll be evaluating.
Full Guide:
- Acquiring & formatting data for deep learning applications
- Word embedding and data splitting
- Bag-of-words to classify sentence types (Dictionary)
- Classify sentences via a multilayer perceptron (MLP)
- Classify sentences via a recurrent neural network (LSTM)
- Convolutional neural networks to classify sentences (CNN)
- FastText for sentence classification (FastText) (Next Article)
- Hyperparameter tuning for sentence classification
Great series!! Really enjoyed reading it!
May be worth adding that the key difference of CNNs is that weights are shared. I.e. while weights _inside_ a particular kernel/filter are all unique, the same set of weights are shared _across_ filters. That’s what allows to detect “features” in the input.