
Though one of the major goals of computer vision is automatic recognition and understanding of natural features, for many applications this level of sophistication is unnecessary and could even be detrimental (due to errors or lack of speed). In applications where an perception is less important, such as virtual/augmented reality systems, or swarm robotics, localization and ground truthing is achieved with the use of fiducial markers (trackable objects in a scene), which serve as easily identifiable artificial features. Over the past year, I have been developing an improvement to AprilTags, a fiducial marker that is used commonly in robotics. This improvement is dubbed ChromaTags (and is a work still in progress)!
ChromaTags were designed as an improvement upon AprilTags by decreasing the computational cost of tag detection and increasing robustness to lighting, occlusion, and warping. We achieved this, in part, by eschewing the standard RGB colorspace in favor of CIELab or YUV and by incorporating color into AprilTag.
As a result, the detection speed of ChromaTag is nearly twice that of AprilTag, allowing use in real time applications, such as the one below… where you can track your glass as you drink (designed for VRBar, more coming soon).
It should be noted that this work was done while at U of I, while I was funded by ISUR, mentored by Joe Degol in the Bretl Research Group, and while I was in CS543 Computer Vision at UIUC working with Bhargava Manja[1]. It is also still a work in progress, and there are several kinks that need to be worked out for the tag to be tracked at a sustainable rate. However, the demo’s created an hosted on my github, everything from chromaTags on a server, to a direct comparison for AprilTags and ChromaTags.
AprilTags
Prior to jumping into ChromaTags, some background knowledge about AprilTags is prudent. AprilTags were developed by Edwin Olson at the University of Michigan[2], and consist of a black and white square with a binary encoding inside. AprilTags work by reviewing gray scale images to attempt to find the tag by merging quads, and searching for the binary encoding inside.

The method is actually really straight forward, and the advantage is that it works relatively fast (depending on the resolution and processing power).
AprilTag Method
1. Line Detection
The first step in the AprilTags identification method is to compute the gradient and magnitude of every pixel, enabling the detection of line segments using efficient methods such as those described by Felzenszwalb[2].
2. Quad Detection
After all of the line segments have been identified, the AprilTags algorithm completes a depth-first search on the line segments. If four lines intersect, then they are a potential quad and need to be checked for detection.
3. Homography and Extrinsic Estimation
After a quad is detected the homography is determined using the Direct Linear Transform (DLT) algorithm[3]. Then, with the cameras focal length, it is possible to solve the PnP problem using RANSAC, providing us with a rotation and translation vector.
Payload Detection
Once the rotation and translation is known it is possible to check the payload of the quad. Using the homography the inside of all of the potential quads are sampled and determined to either be a known tag or not a tag.
One of the more important insights by Olson was the development of the AprilTag coding system. It was designed to:
1. Maximize the number of distinguishable codes
2. Maximize correctable bit errors
3. Minimize false positive confusion rate
4. Minimize the number of bits per tag (minimizing tag size)
This was accomplished by maximizing the Hamming distance between the tags, thus making them more distinguishable. Critically, the Hamming distance from all other tags are bounded from below, no matter how the tags are rotated (i.e. 90, 180, 270 degrees).
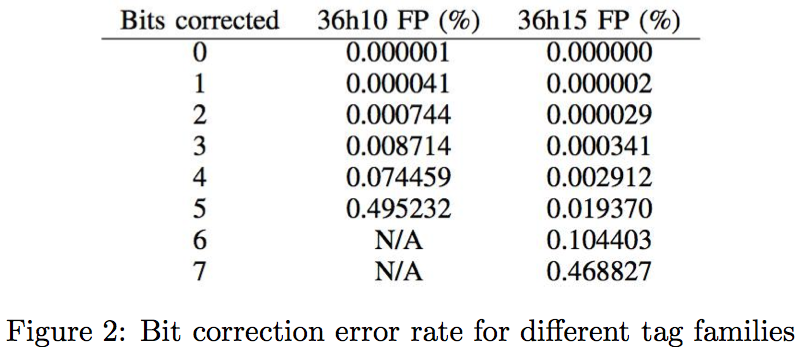
Based off experimental data, AprilTags was a significant improvement over prior methods such as QR codes or the ARToolKit[3]. Notably, AprilTags are significantly better at reducing false positives, specifically those which occur due to either part of the tag being covered, lighting issues, or errors due to color. Essentially, the algorithm will identify a tag incorrectly or may not identify it at all, which can be catastrophic in instances using robots, or break an augmented reality experience.
For reference, a 6×6 AprilTag can correct 3 bits and still have a false positive rate less than one percent of the time (from Olson’s paper[2]).
ChromaTags
Let me be clear, ChromaTags currently are still in development. However, we have finished a large portion of the theoretical work and have recently developed an initial tag for comparison purposes with AprilTags.

The goals behind developing chromaTags are to:
A. Increase tag identification speed
By decreasing tag identification time it will improve the ability to track the tag in realtime. For example, improving tag tracking from a few frames per second to forty or fifty will make a drastic difference in an augmented reality experience.
B. Reduce false positives
In Olson’s AprilTags paper, it was noted how important reducing false positives can be. Any improvements with this in mind would improve the robustness of a tag.
C. Minimize the size of a tag
AprilTags are often the size of a sheet of paper, roughly 15cm across. Developing a tag that is 3cm across would be a dramatic reduction in size, and would enable a wider range of applications.
D. Maximize the number of codes
Given the requirement for every AprilTag to have a hamming distance greater than a certain number (ideally 10 or 11), it severally limited the number of tags. Rather than having only a few thousand tags, we desired to increase that number to millions.
With those goals in mind, we decided to take a somewhat different approach than previous tag methods. In computer vision it is common to use either edges or blobs for identification purposes. Usually, this is done using gray scale images, as they are quicker to process, and supposedly contain most of the data! Unfortunately, there are often many edges in a scene, perhaps thousands, and every edge does not always provide important data.
Just take a quick exercise and look around the room. How many edges do you see? Don’t forget to look at the train of the wood, the lines between tiles, brick, ceiling. Literally, everything has a few edges! Now, recall the earlier statement that AprilTags has to do line segmentation and quad detection on every line. This is part of the reason the tracking is so slow, especially at high resolutions.
The Colorful Insight to ChromaTags
ChromaTags really comes from the insight that using color even though we have three times more information (i.e. three color channels), would speed up tag tracking/processing. If we again take a step back, we are already placing something in a scene that we can track, why the hell is it so difficult to find/identify? The main issue, is that the tag requires some processing on every line. If instead, we only focused on a few lines we need to track (to find the tag)… we could dramatically speed up the process!
It turns out, that this insight enabled us to process frames/scenes roughly twice as fast, while at the same time, allowing us to encode twice as much information! We cannot however, use RGB image (red, green, blue). RGB images contain light information, and can easily be affected by changes due to shadows, and there are other issues I will skip for now.
Instead we use a color space called CIELab (or lab), where:
- L channel represents the light channel
- a channel represents colors green to red
- b channel represents colors blue to yellow
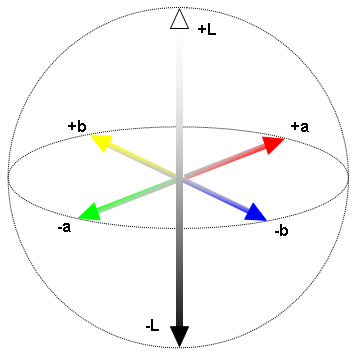
I’ve written about this quite a bit before, as I spent many hundreds of hours researching color spaces. One interesting note is that it drastically improves edge detection, because it removes most of edges on an object, and leaves only edges separating objects (as I wrote about here).
The beauty of this insight, is it made it possible to make a chromaTag directly comparable to AprilTags. We simply encoded two AprilTags on one chromaTag and comparing the tracking speed.

It is important to note, that this tag generation is not achieved by simply mixing colors in the standard RGB color space, that would not achieve the appropriate colors. Rather, the colors we select for the tag are at the corners of the Lab color space, such that the a channel and b channel would both be at the extreme when selecting a color, enabling a high gradient to be achieved.
ChromaTags Method
Then, the identification method could be done in a simply three step process!
1. Conversion from RGB to Lab
A relatively simple step, achieved using OpenCVs conversion BRG2LAB function.
2. Separating of a and b channel
Once we have an Lab image, we can separate out the a channel and then hand the new frame to the AprilTags algorithm. The a channel tags are more prominent, and fewer superfluous line segments are discovered, so that is the first to be sent to the AprilTags algorithm.
3. Run AprilTags algorithm again
Initially the AprilTags algorithm is ran for one color channel (the a channel). After a tags location was identified, then the algorithm is ran again over a very small localized region for the b channel, and that tag ID is also identified.
The methods true value comes from removing many of the lines inherent in the scene without the need to specifically check them. For comparison purposes, you can see below that the AprilTags detection detects far more line segments, and in turn is slower.

Why ChromaTags?
To me, this is really important for two reasons:
- It was important for me to prove that image processing is actually faster using colored images. Many computer vision applications run under the assumption that edges are either the most important or one of the most important features of an object/image. However, how many computer vision experts determine a useful edge seems to be naive and less accurate. Many computer vision applications may have the wrong premise of a useful edge, and should be reevaluated to produce better results.
- Fiducial markers are used in robotics, augmented/virtual reality, and computer vision applications. Any improvement or new fiducial markers can greatly impact the accuracy of those applications, and provide a better experiences, working conditions, and cooler games.
Future Work
There is a ton of work to do, regarding both the demo applications on my github, the scientific evidence, and eventually iterative improvements (perhaps this tag model isn’t the best). It is relatively easy to prove that chromaTags will always be at least as good, if not better than AprilTags. Logically, this must be the case because every possible edge appears in a gray scaled image, and anything will be an improvement. However, it is not a mathematical proof, and proving that using color is always better, would be quite a feat (if possible).
Another goal is to move away from using AprilTags’ basic algorithm, as changing colorspaces presents many opportunities for optimization. For example, the fact that certain types of edges can be thresholded away in Lab space makes possible the use of better algorithms for quad detection and line fitting. This thread of inquiry presents might present major advancements in the state of the art of fiducial systems.
Finally, I plan to write an article (and perhaps publish a paper), about the optimal color space for given tasks. For example, man made object often include the color red, where the color red much more rarely occurs in nature. Creating a mathematical proof and algorithm to generate a color space for any generic job would be interesting and fun (and has been done to some degree).
As always, stay tuned for updates! I have a ton of new stuff bottled up and ready to be written
Related Articles
- University of Illinois Urbana-Champaign Grade Distributions
- The Opportunity Cost of War
- Edge Detection in Computer Vision
- Analyzing Email Data
- PCA: Principal Component Analysis