
April 1, 2014 – July 1, 2014
Over the past three months I have been attempting to build my blog. It’s been fun, I’ve learned a lot and would like to share what I have learned with the world! I previously posted what I learned in One Month of Blogging, and suggest you read that article as well. Before I share what I have learned, I first would like to explain my “purpose” behind this blog in order to give you a better understanding about why I do what I do.
I began blogging regularly in 2009; however, I would not say I began regularly blogging (especially on austingwalters.com) until March 2014. At that point I posted an article Please Excuse my Grammar, which made it to the front page of Hacker News and more or less spurred my interest in blogging, along with my friend Robb Seaton writing his blog. Further, I had just finished reading the notes I had written about studying (what improved/damaged my grades) and confirmed that the more I share my knowledge the better I learn. I then started to get in the habit of blogging, building content, etc. and in mid-April 2014 I began a campaign to build my blog.
Thus, began my blogging adventure!
Purpose
If I had to pick three reasons why people should read my blog:
- I have a reasonable amount of experience helping people
- I believe my articles are of decent quality
- I have a skill set many people desire to obtain
I attempt to produce a single stand alone article two to four times a week, allowing people to follow me and learn a topic related to Computer Science (at slightly above the beginner level). As time progresses, I hope to continue to share what I learn and help people. I, however, like to be clear in the fact that I write this blog for myself. I believe and research supports me, in the fact that sharing what you know, constantly testing yourself, and integrating knowledge with what you already know is important to maintain knowledge in the long term. Therefore, I write my blog for the following reasons:
- Learning though blogging
- Maintaining an active directory of notes
- Obtain readers who may employ me (via google helpouts or job offers), I have already received some offers (which was surprising to me)
- Receive feedback from my readers and improve
- Learn how to build a website, allowing me to launch other (profitable) websites in the future
That last point is the most important and the purpose of this article. I have business ideas constantly pouring out of my brain, and I even keep a journal of (just) the top 5 I can think of per day. I then review the ideas periodically and determine which ones are worth keeping and which ones are not. Usually, two to four of the ideas stay, meaning I currently have a back log of several hundred ideas.
What is the purpose in me telling you this? My blog has been (more or less) dedicated to implementing a subset of those ideas, providing feedback for future ideas and better content on my blog. Often, I will even try new things I think will make my blog worse, which may seem counterintuitive, but it helps me hone in on specific things to avoid. My apologies if this has impacted your readership in anyway, I will never effect quality of posts, usually just layout, where I advertise, etc.
Analytics Overview
Over the past three months I have gathered a lot of data. For simplicity’s sake, I will attempt to provide the information in a straight forward manner after applying some analysis (if possible).
Let me begin with with the number of sessions/visitors I received over the past three months. There have been three phases to my blogging:
- Mid-April – Mid-May: Technical content posted and shared on Hacker News and Reddit, cross-posting where ever possible.
- Mid-May – Mid-June: Less Technical Content, occasional shares on Hacker News and posting only once on Reddit. Posted each blog post to Twitter, Google+, and Facebook using hashtages, Stumbleupon was occasionally used.
- Mid-June – Early July: Stumbleupon was heavily used, occasional cross-posted on Reddit, a few more technical blog articles were written.
 The above makes it pretty clear that cross-posting on Reddit and writing technical pieces were the “bread and butter” of this blog. Once I stopped posting to /r/Programming as well as cross-posting the number of visitors on my website dropped roughly 50%. This makes sense after reviewing the top traffic sources to my website.
The above makes it pretty clear that cross-posting on Reddit and writing technical pieces were the “bread and butter” of this blog. Once I stopped posting to /r/Programming as well as cross-posting the number of visitors on my website dropped roughly 50%. This makes sense after reviewing the top traffic sources to my website.

Reddit makes up 38.91% of my viewership and (direct) / (none) make up another 37.17%, which is usually Hacker News since they use “https” no referral is sent[1]. This means roughly 80% of my traffic comes from social websites I interact and share my content with. If we want to break it down to a bar chart:
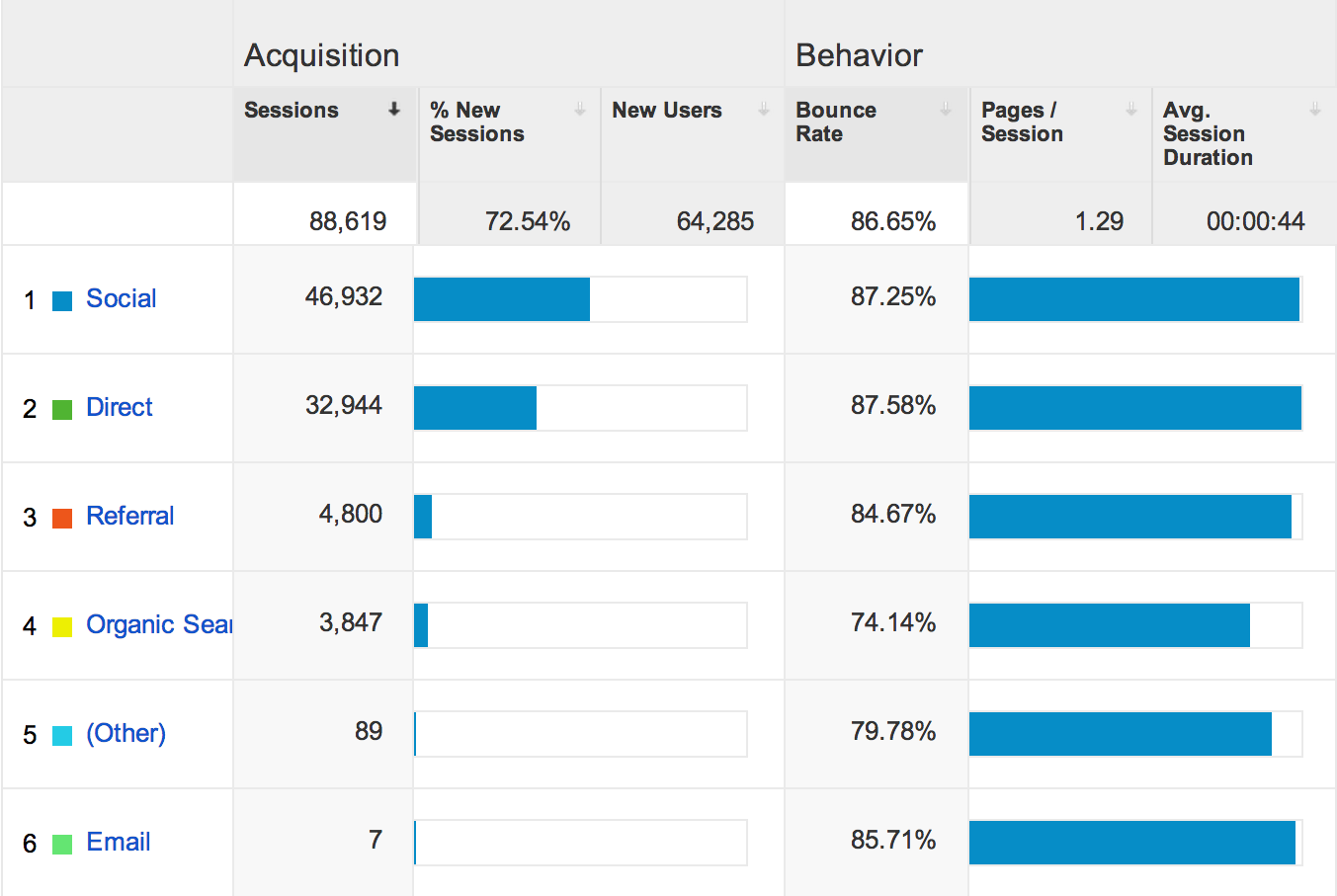
Reviewing the bar chart above, it becomes clear how much social sharing is important to the survival/growth of my blog. All, but 8,743 visitors or 9.658% of my traffic comes from social websites. Unfortunately, those social websites also have the highest bounce rate. If we break down each channel further, we receive some startling facts.

Visitors through Organic Search, (non-social sharing website) Referrals, and Emails are of much higher quality. They often have visited the website multiple times, have a much higher probability of viewing multiple pages, and will spend double to quadruple as much time on each webpage compared to someone from a social sharing website. Considering most of the visitors through these modes have visited the website before they clearly feel it is worth their time to return, it makes sense they have a higher average time on the website.
What I find most interesting is Organic Search, only 35% of viewers who accessed my website through Organic Search are “new visitors.” I found that simply astonishing, but upon some contemplation I recalled Google uses the websites you visit, search for, etc. to “improve your search.” Implying that many of my viewers will search for my articles again or will again bump into my website when researching a topic. My guess is that this occurs because I have written a series of articles (10+) related to multithreading and often individuals will run into similar issues. Since I’m on the subject, let’s take a more in-depth look into my organic search results.
Organic Search
About a month ago my friend Robb suggested using Google’s Webmaster Tools to start tracking my organic searches, following his suggestion I set up an account and have since began tracking how well I have been doing.
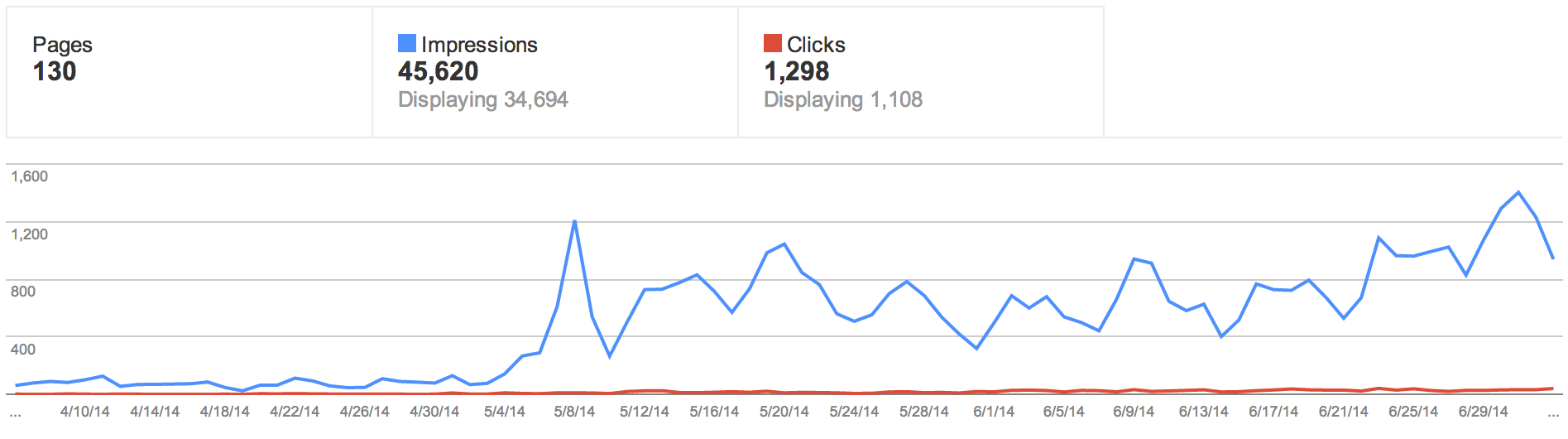 Webmaster tools provides you with a break down of key phrases in which you appeared as well as the number of impressions, clicks, CTR (click through rate), and (most importantly) where you appear on the page.
Webmaster tools provides you with a break down of key phrases in which you appeared as well as the number of impressions, clicks, CTR (click through rate), and (most importantly) where you appear on the page.
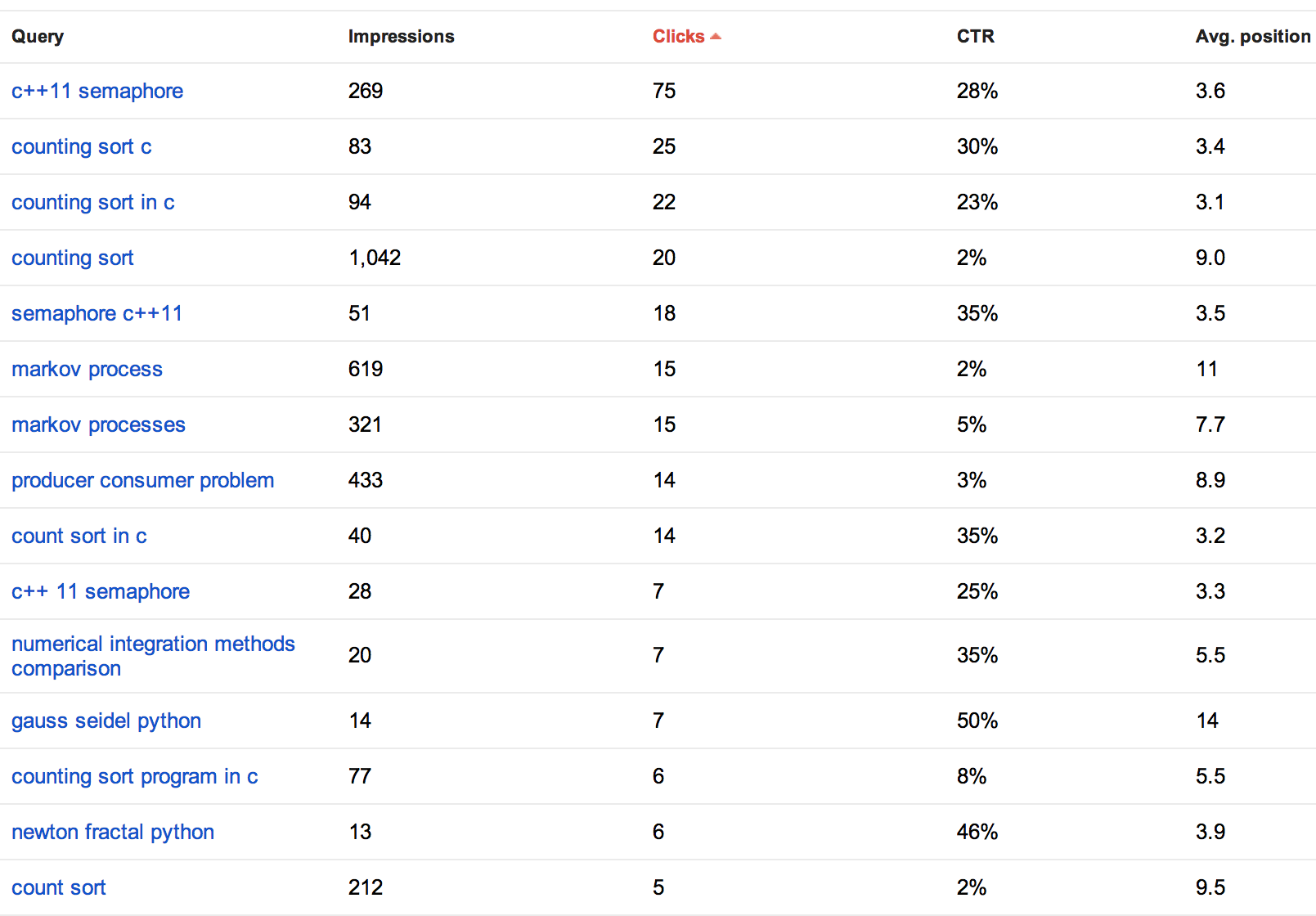
You can view the webpages as well:

Using this information, I can compare it to the average time per page from my organic search section of my analytics. This provides me with a list of my most capturing webpages, how well I am currently doing in organic search and where I should attempt to obtain more referral links and in turn more “Google Juice.”
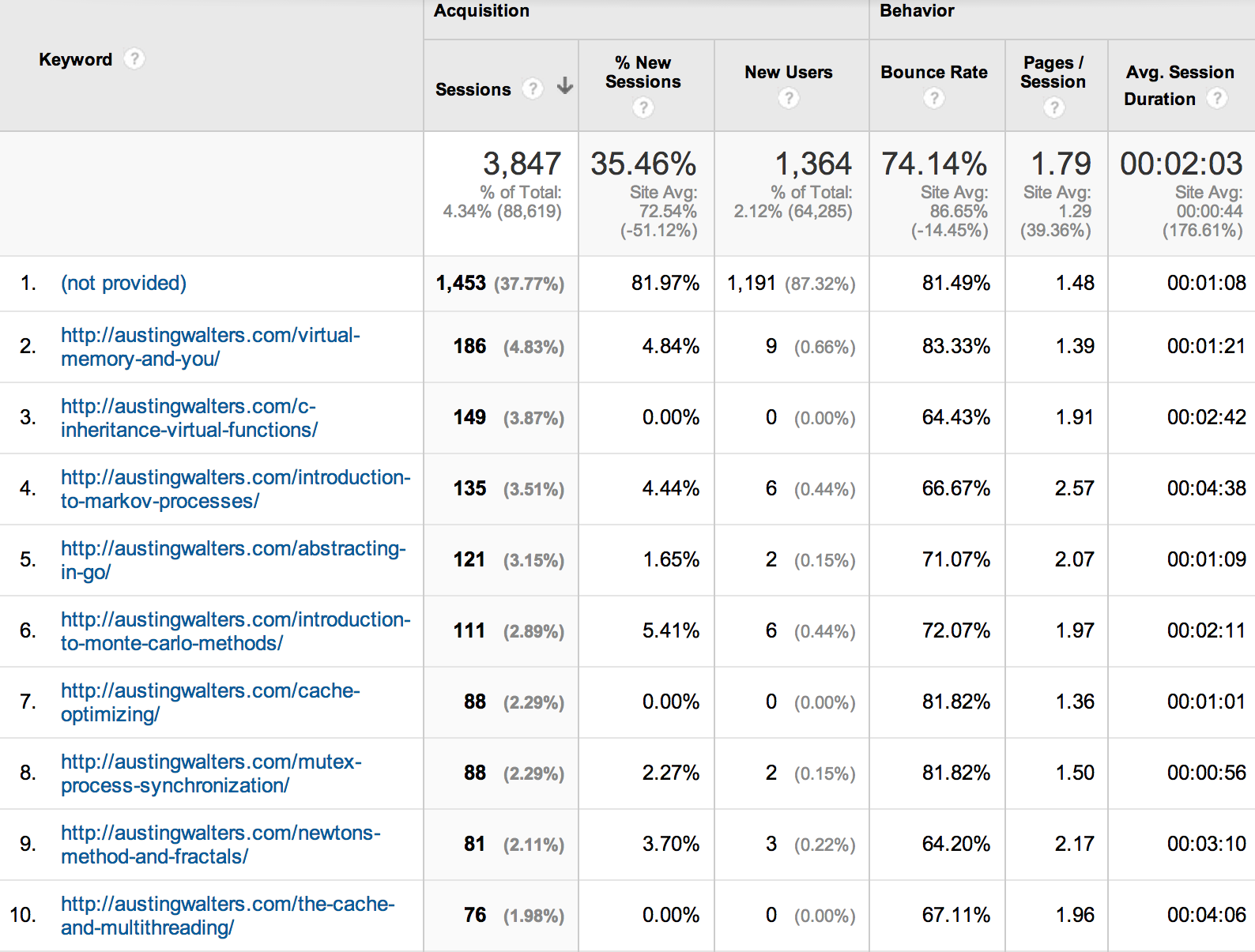
This is by far one of the most important and personally most overlooked areas of growing a website. For example, the average visitor who views my article on Markov Processes via an organic search will view 2.57 pages on average, stay on the webpage for an average of 4 minutes and 38 seconds and only 66% of visitors bounce (a low bounce rate).
How do you increase the “Google Juice” for this topic? Well, that’s a discussion for another time, but the best way is to post your article in social media sites such as Facebook, Twitter, Google+, Reddit, Hacker News, StumbleUpon, etc. In doing so, you ensure people view your post and occasionally will repost your article or reblog your article. Either way you are gaining more “Google Juice,” especially if they are popular on the internet. My goal over the next three months is to maximize my websites followers, but I will be keeping an eye on Organic Search and distribute any information I uncover.
If you would like to view the full list of queries and URLs:
- austingwalters.com | Top Search Queries | April 4, 2014 – July 5, 2014
- austingwalters.com | Top Search Urls | April 4, 2014 – July 5, 2014
User Flow
Receiving traffic is relatively easy and straightforward, it’s converting users to another article on your blog that is important. Users who view more than one page are much more likely to subscribe to the RSS feed or (recently added) mailing list. Google Analytics provides some wonderful features to view this, though I do have some suggestions if they ever ask on how to improve their service (give me a table of data!).
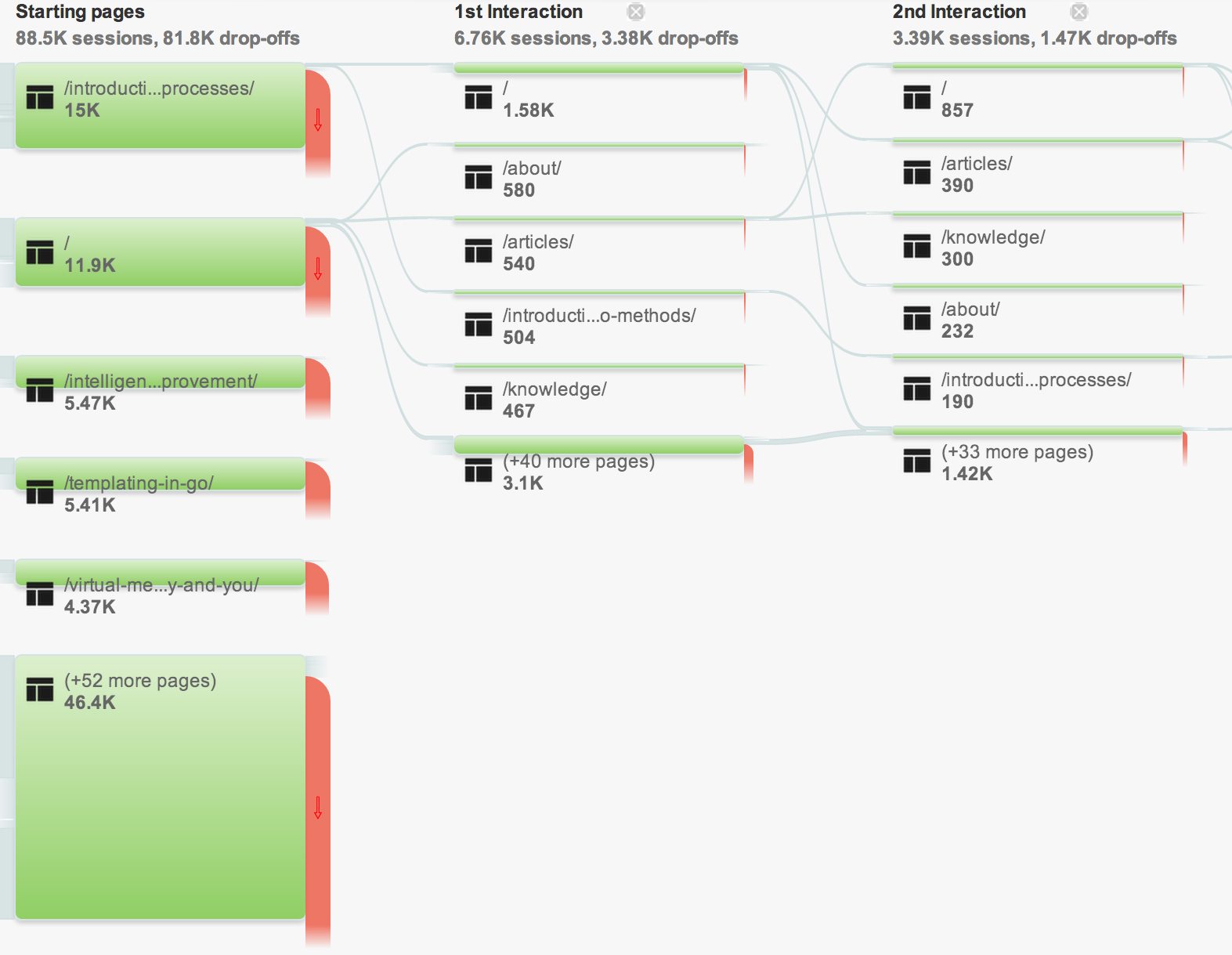
It is extremely clear in this visualization how large my drop-off rate is, but this does provide some valuable insight. For example, if I click on the Markov Processes article:
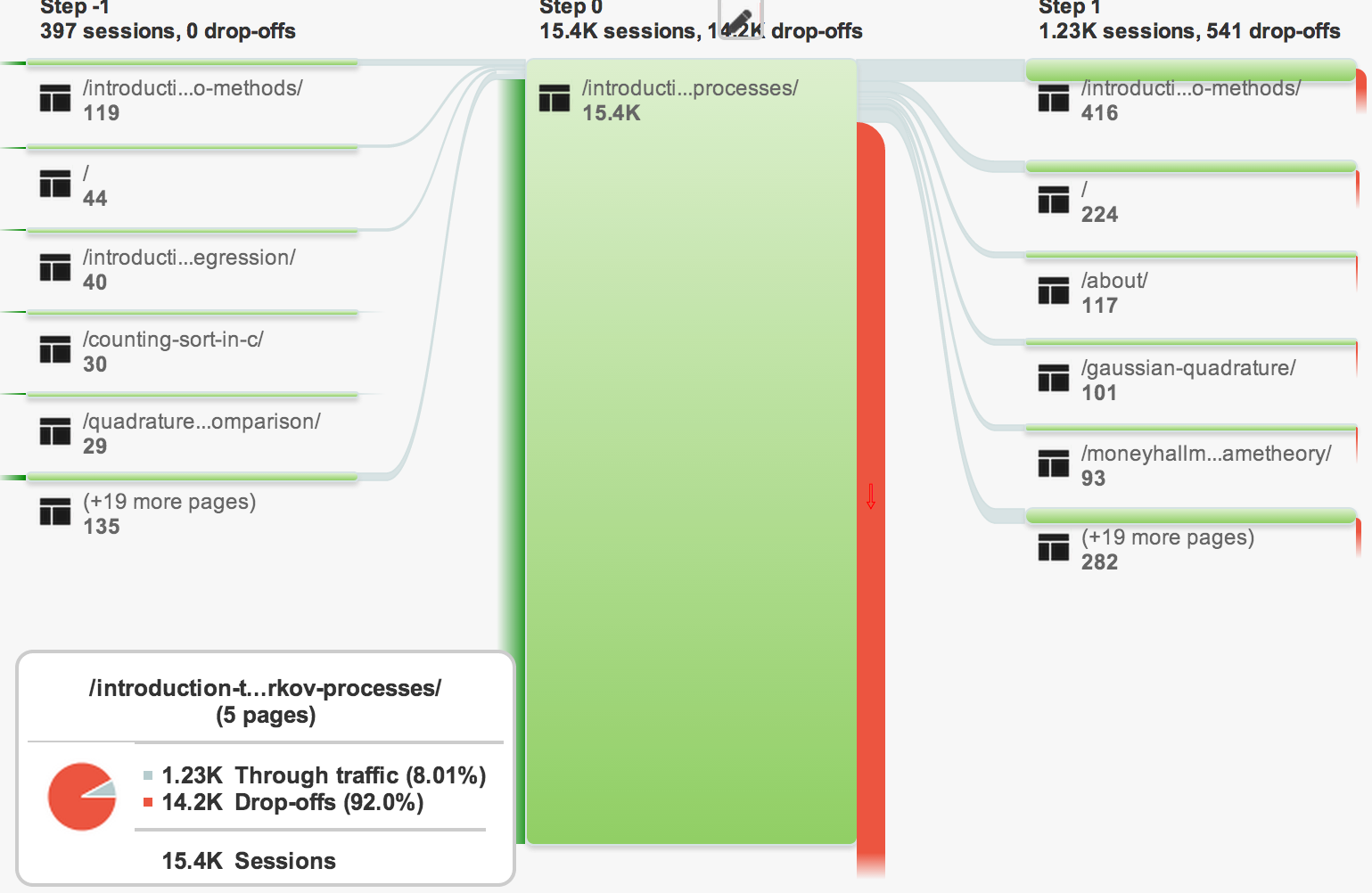
I can view where my users enter and leave the page. What is interesting here, is that the article most traveled to after visiting my article titled Introduction to Markov Processes, is my article titled Introduction to Monte Carlo Methods. My assumption being the title is similar in structure, name and even topic so many people will view the page. Unfortunately, the Monte Carlo Method article is not as popular (I’m guessing because the topic is pretty boring and better understood), so most of my users will drop off at that point. Meaning, it is likely better to direct my users to a different page in my “Related Articles” section than the dud Monte Carlo article.

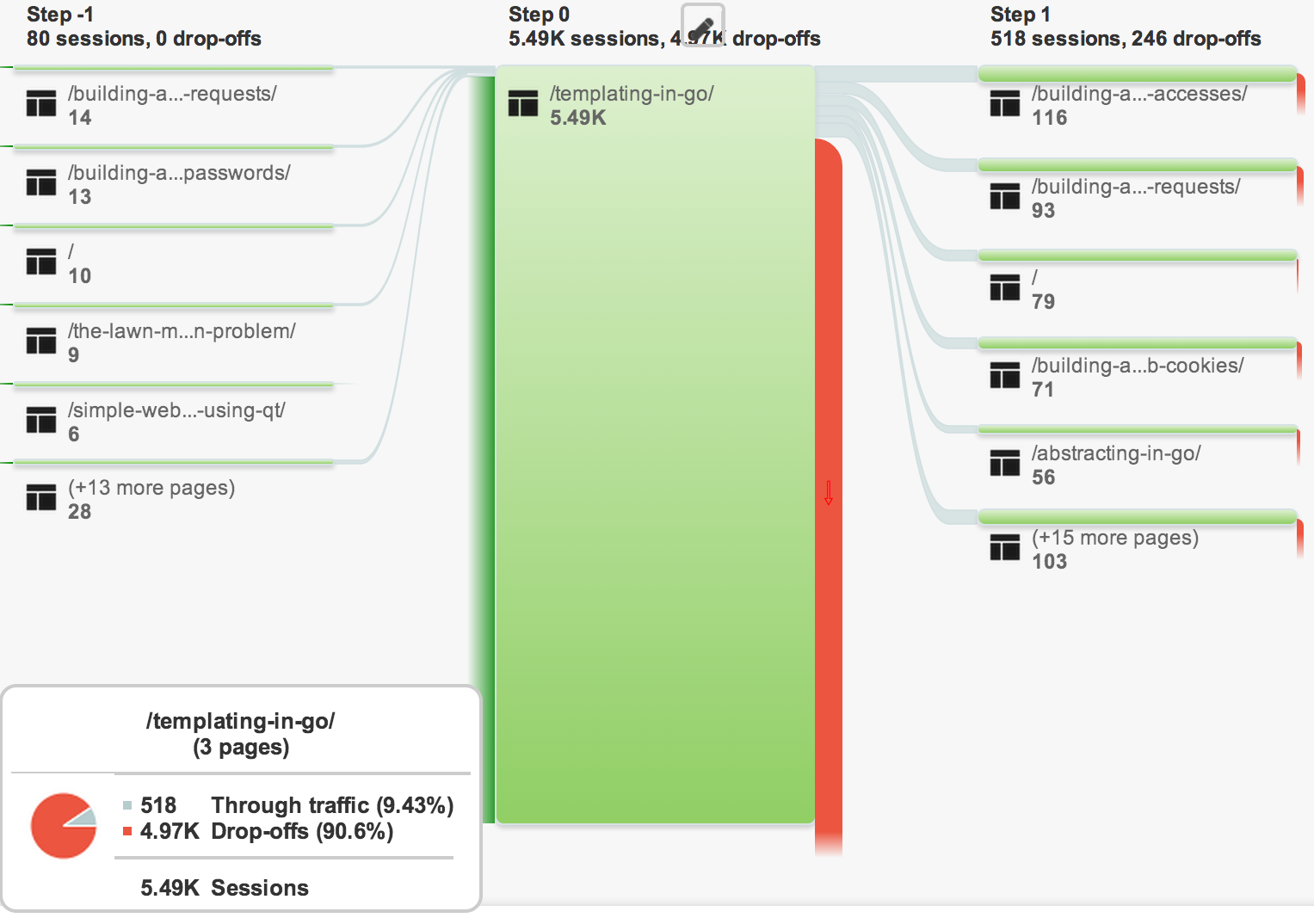
Another one of my popular articles, which has a lower drop-off rate, is Templating in Go. Even after the original article, the “Related Articles” have a much lower drop-off rate than the Monte-Carlo method. The lower drop-off rate implies that the articles are more highly correlated, better written, or attract similar readers. To me this makes sense, because the article Templating in Go was the first in a series of “Building a Website in Go” articles.
Followers
Whether through Email, Twitter, or RSS followers are always the most active users (i.e. bounce the least, visit the most). Until recently (June 15th) I was only using Twitter and RSS to distribute my content, I have since started using Google+ and a mailing list to grow my followers. Further, I added a hash tag #Programming to my website on Feedly, improving my search-ability and in turn I should gain a fair amount RSS followers.
 The mailing list has also been a wonderful improvement, those are the “best” followers and have by far the highest activity rates. Although my mailing list is only three weeks old and I have not had any big articles recently, it still has 27 followers to date and based off my first campaign a relatively high click through rate.
The mailing list has also been a wonderful improvement, those are the “best” followers and have by far the highest activity rates. Although my mailing list is only three weeks old and I have not had any big articles recently, it still has 27 followers to date and based off my first campaign a relatively high click through rate.
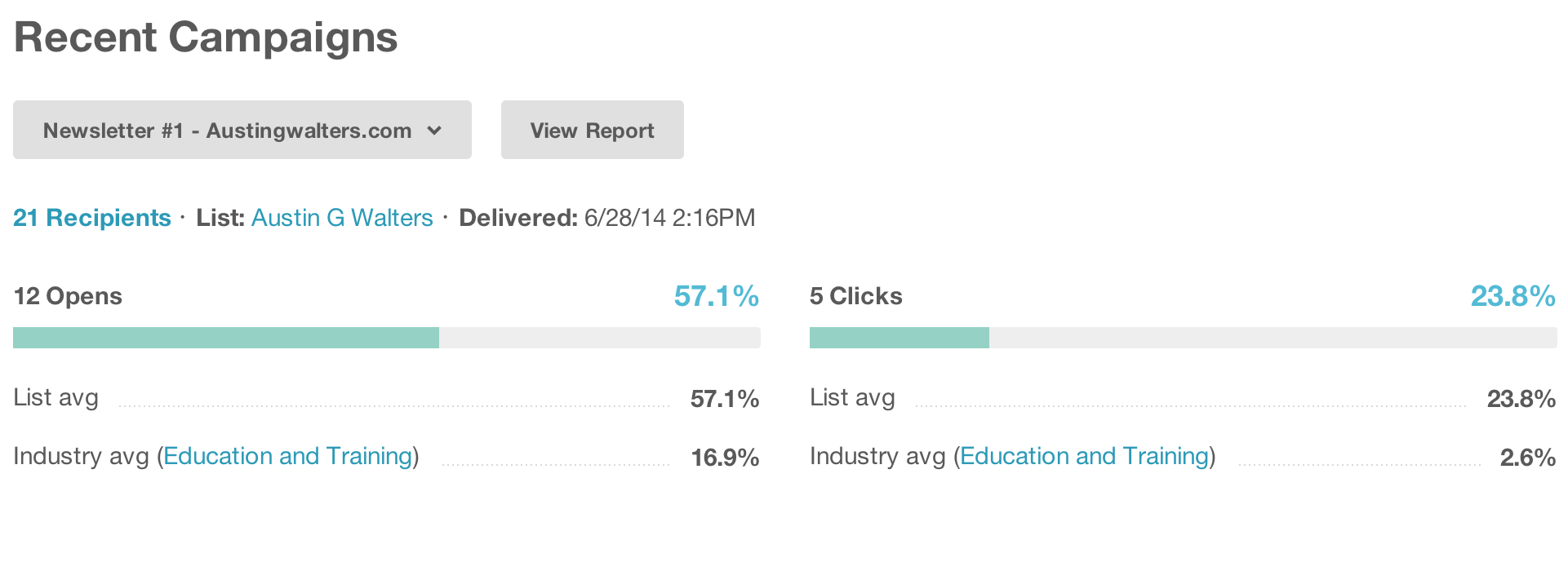 MailChimp also lets me view which links are clicked on the most via a “page map,” which is both really fun to use, but also very informative. I can gain insight as to how placement works and even break down users into interest groups based off of what links they click.
MailChimp also lets me view which links are clicked on the most via a “page map,” which is both really fun to use, but also very informative. I can gain insight as to how placement works and even break down users into interest groups based off of what links they click.
For example, there was a greater interest in articles over site changes, leading me to the conclusion not to inform my readers of site changes (and in turn improve my chances of maintaining readership).
It is also interesting to note that since I spent a month not posting nearly any technical articles, my RSS readership has declined notably (about 33%).
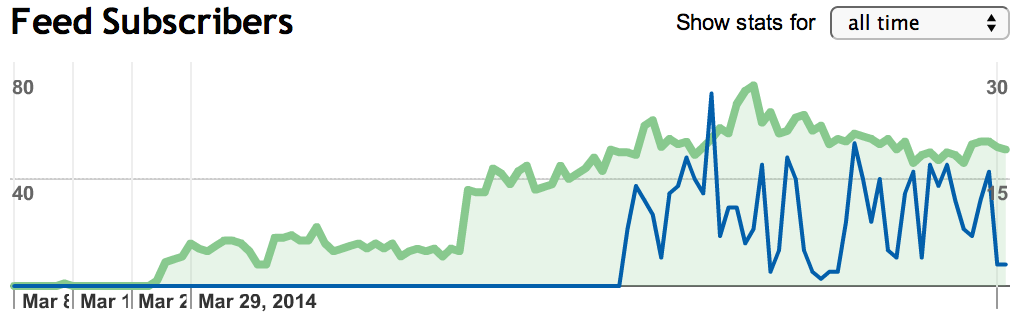
The number of subscribers lost also correlates pretty nicely with the number of followers I have gained via Github as well as the number of commits:
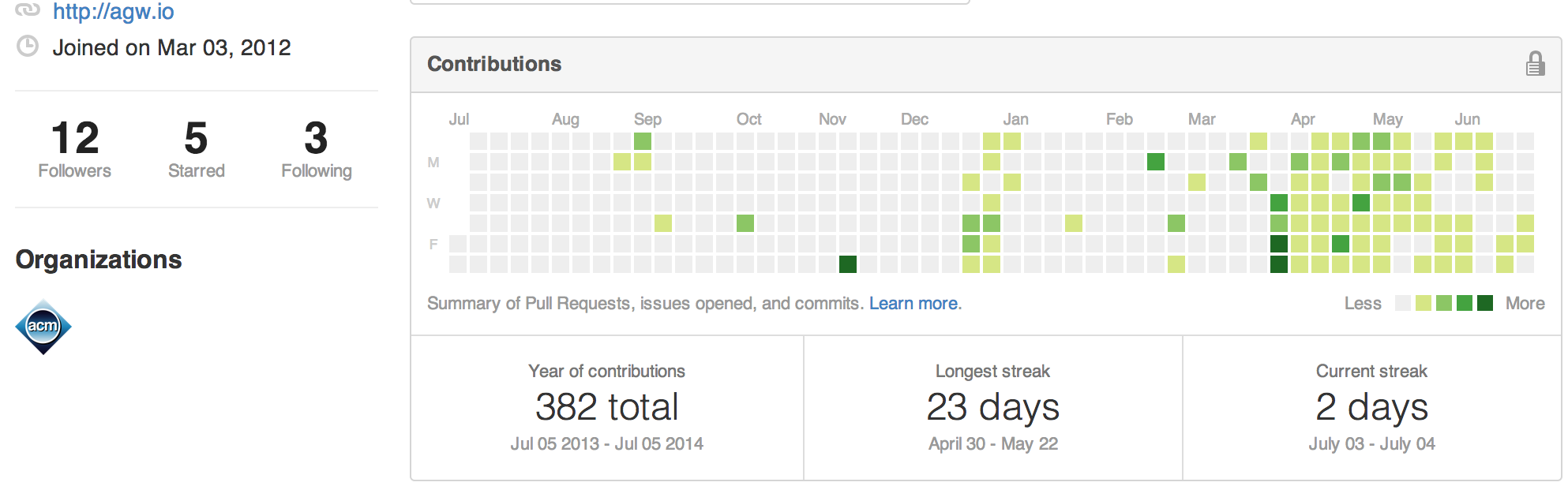
Thus, leading me to focus more heavily on Computer Science related subject matter for the following months.
Although it hardly is worth mentioning, my Twitter followers continue to increase (though at a much slower pace than previously, up from 44 to 80 in three months.. Though these are far less active followers and in turn are not all that important in such small numbers.
Experimentation
Over the past few months I ran a couple of experiments related to “timing” of posts. Although I have since deleted the data (I’ll get to that in a second), it has been fruitful and I would like to share the currently unproven, but likely discovery. I have always been troubled by the articles that have “made it” and those that have not. Specifically, there are two articles that confuse the heck out of me:
- I/O Multiplexing Using epoll and kqueue System Calls – Didn’t “make it”
- Multithreading: Semaphores – “made it”
Multithreading: Semaphores is one of my popular posts and it obtains me the most Google traffic and is ~500 words, most of which is code, and literally supplies nothing new, it is merely an example of using a semaphore in C++11. I/O Multiplexing, on the other hand, is way more unique and useful. I could not find a side by side example of epoll and kqueue being used so I made one, which I thought would interest many people. It turns out it didn’t hit the top of HN or Reddit.
Posting Time to Hacker News and Reddit
In an attempt to discover why, I began deleting articles from HN (Hacker News) and Reddit after an hour if they did not receive many up votes. I would then repost them a day later at a different time in an attempt to determine if it was just “time-of-day” bias. I had to use the same article, rather than a new one, to ensure it was not the quality of my article that made the difference, but rather the readership. Depending how awake my readers are or how many other posts are sharing their attention at a given time, could dramatically influences the possible success of an article.
Based on what I saw, there is definitely a fairly large bias. Of the 20 posts I attempted to do this with (between HN and Reddit), 5 of the 20 received a significant bump in votes and 2 of the 20 went from receiving no votes on HN to the front page. That is a really big deal, considering that is literally tens of thousands of views, reposts, referral links, “Google Juice,” etc.
The reason I deleted most hard numbers for this data is I received an Email from Hacker News:
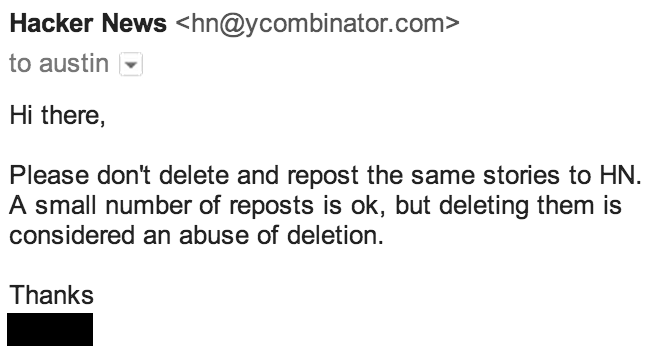
The response I received was more than fair in my opinion, I was being rather “snaky,” so I immediately stopped deleting my posts. I deleted the hard data because the sample size was much too small for any reasonable analysis and rather than releasing inaccurate information as gospel or even as a hint of truth, I would rather just rid myself of it. What I would like to share with you, my faithful reader who has made it through 2400 words, is this:
- There is (in my opinion) reason to believe that posting in the morning, 5 AM west coast time (San Francisco) on Hacker News is the “best time”.
- The night at 6 PM west coast time is the worst time to post.
My guess is that 5 AM west coast time is the time everywhere else in the world is active, and the rest of the people in major cities in U.S. (not on the west coast) are on their way to work and checking their RSS feeds as well as Hacker News.
Then when the west coast wakes up (home to the a little over half of the tech companies in the world) the post (if successful) is hanging around the front page or in the “new” section of Hacker News. Plus, very few people post at 7 AM, so you can be one of the few for several hours and in turn increase the probability you’ll rise to the top (though quality content is the best indicator of rising to the front page). I would like to remind you, that this is not statistically confirmed. It is however, logical and there is some statistical evidence pointing in that direction (though unconfirmed).
In order to better understand this, I began tracking the votes over time, locations I post to as well as titles, time of day, date and up votes. I hope to release all the data via my mailing list when I have enough statistical evidence.
Closing Remarks and Future Outlook
I have learned a lot blogging and I have a lot further to go. This summer has been rough for me. I am working ~40 hours a week, trying to hang out with my girlfriend, I have a new (naked) Peterbald Kitten, and am trying to work on Open Source project and this blog all at the same time (somewhere in there I manage to sleep). The upcoming Fall 2014 semester is going to be the beginning of my senior year at the University of Illinois Urbana-Champaign and I would like to blog about the various subjects I learn. Courses include:
- Machine Learning and Signal Processing (CS 598)
- Fundamental Algorithms (CS 473)
- Probability and Statistics in Computer Science (CS 498)
- Senior Thesis (Computer Vision related, but I won’t blog about that)
If you are interested in those subjects, I recommend following my RSS or Email (sign up below). I will also likely post topics regarding learning, self improvement, and perhaps Irish (since I’ll be practicing daily).
As for specifics about experiments I am doing and building the blog, I intend to continue tracking posting times and trying to link it to success. I will also be attempting my first tracked A/B tests as well as add some new features if I can get around to it. I created a Mobile and Desktop version of the website recently and it reduced my bounce rate (as of this week), but I need more time to tell for sure, so expect updates next time!
I didn’t receive an email notifying me of the last two articles, though I’m supposed to be subscribed. (I did check my junk mail folder as well.)
I am amazed this site has such traffic, though as you said, I suspect it’s because it’s more technical and less “my opinion on stuff.” People use the internet to learn stuff for free, whether watching a YouTube video or searching for articles to glean from. I am kind of surprised there aren’t more comments if you’re receiving that many views! Is that because the articles are posted in more than one place, and the traffic is there instead?
The problem with linking to Reddit is while you get tons of views, it doesn’t look like you’re getting very many return visitors. I had the same happen with one of my entries, someone else linked to it and though a couple thousand people clicked that link, only a couple dozen actually checked out the rest of my blog and only a handful have stuck around. Pageviews are great, but returning readers are what you want to aim for. Do you get many upvotes or replies when you post a link on Reddit?